




Across research institutions, personal devices, and private companies, humankind is gathering a huge amount of information about ourselves at an incredible rate.
This could be an amazing thing: the open data movement has done a great job of explaining the benefits of increased access to data: advancing science, increasing human knowledge, democratizing knowledge.
But we know not all data can be open:
- Sometimes, important data privacy protections that make it difficult to share data across institutions.
- Sometimes (especially in the private sector), sensitive data is financially valuable: every institution you share data with then becomes a competitor.
As a result, a lot of scientific information is often kept safely locked away in data silos - sometimes at the expense of our ability to make scientific progress and collaborate. The inability to share data also contributes to our issues with reproducibility, accountability and transparency in science.
The Solution: Data Science Without Access
We want to make it possible to learn from data you can't have access to, without sacrificing privacy.
We're building infrastructure for easy remote data science.
We want to allow you to extract insights, train models, and evaluate results on data — without anyone copying, sending, or sharing that data.
You get your stats/model/results, the data owner keeps the data.
What could we do - if this was possible and easy?
- Perform larger, aggregate statistical studies — sample size and generalization is an issue in many areas of research
- Frictionless collaboration between research institutions and departments
- Use more real-world representative datasets — so models don't fail when they reach the clinic
- Use more diversified datasets to ensure our research better serves our world's population — current datasets can often feature a disproportionate number of young, university student subjects, which results in training data that is not representative of our patient populations
- Improve academic transparency and accountability — not everyone can publish their data alongside their journal article
- More meaningful comparison of results — imagine being able to easily test your method on another group's dataset to fairly compare your results to theirs - this is the standard in machine learning research, but not common in many scientific fields
This would be very powerful — and it will take us time to reach that vision. But how do we get started?
Step 1 - Introducing 'Duet'
Before we can have massive open networks for data, we need to be able to let two people - one with data, and the other with data science expertise - do an experiment without revealing the data itself.
We call this OpenMined Duet.
This is our MVP (minimum viable product) of that final goal.
Duet enables remote execution and permissioning of tensor requests from a data scientist to a data owner’s private data with a simple python notebook. How? Skip below to the 'technical details' section to see how.
What's Next? Introducing OpenGrid
- Create a Data Registry: The data scientist needs to know what data is out there. A data owner can register their dataset (describing details about it - not uploading it anywhere). The OpenGrid Registry is a website to connect these people, so they can schedule a Duet. The OpenGrid Registry also hosts models. It's like craigslist, but for datasets and models. Go ahead and register a dataset or model today.
- Offline Training & Evaluation: Sometimes, scheduling a call is difficult across time zones. Offline training & evaluation would make this accessible across time zones, on an as needed basis.
- Revshare, Reputation & Billing: For some institutions, these will be the strongest incentives. You can listen to Nick Rose explain these in more detail at 7:40 in his PriCon 2020 Talk.
The Details: How exactly do I use Duet?
I encourage you to watch Nick Rose explain this at 5:10 in his PriCon 2020 talk, but to demonstrate the code at a glance:
1. The Data Scientist and Data Owner each open their own python notebook (located anywhere worldwide).
2. The Data Owner creates a Duet object and connects to the grid. Easy to copy and paste instructions are provided containing a unique identifier which can be passed to a scientist over chat or verbally.
import syft as sy
duet = sy.launch_duet()
> Send the following code to your Duet Partner!
> import syft as sy
> duet = sy.join_duet('40a9c3d4a93bd37ae43fe06673fef351')3. The Data Scientist takes the ID and connects to Duet, receiving a unique Client ID to provide back to the Data Owner to confirm the connection.
import syft as sy
duet = sy.join_duet('40a9c3d4a93bd37ae43fe06673fef351')
> Send the Duet Client ID back to your Duet Partner!
> Duet Client ID: 0c653d3d88097cff6638ec5d159e96fc4. The Data Owner imports torch, and then creates two normal tensors, adds special descriptive tags and then hosts the data by calling send and setting searchable to True.
import torch
data = torch.tensor([[0,0],[0,1]]).tag("data")
target = torch.tensor([[0],[0]]).tag("target")
data_ptr = target.send(duet, searchable=True)
target_ptr = data.send(duet, searchable=True) 5. The Data Scientist can now check the Duet store looking for objects tagged as “data” and "target".
duet.store.pandas
> ID Tags
> 0 <UID:593c562c-116b-419d-8c32-e97c271af6a2> [data]
> 1 <UID:6228f284-667d-493a-bbcd-3ec839604de1> [target] 6. The Data Scientist can now get a pointer reference to these objects by indexing the store. This returns a pointer to that data, which can now be used as though it were a regular object.
data_ptr = duet.store[0]
target_ptr = duet.store[1]
print(data_ptr)
> <syft.proxy.torch.TensorPointer at 0x138d06730>7. Actions executed on pointers return more pointers which can be chained, however to get the actual data behind the pointer a permission request must be made. These can be made as blocking or non-blocking requests depending on the need.
sum_ptr = data_ptr.sum().item()
sum = sum_ptr.get(
request_block=True,
name="sum",
reason="To see the result",
timeout_secs=30,
)
print(sum) <---- waiting for the above line to complete first8. On the Data Owner side a list of available requests can be viewed and accepted or denied.
duet.requests.pandas
> Request Name Reason Request ID
> 0 sum To see the result <UID:8633a6a0-...-cf2242a67f7c>
duet.requests[0].accept()9. Done! The next line of the Data Scientists notebook executes and prints the output as expected.
print(sum)
> 1For more on Duet, make sure to See Nick's talk for details.
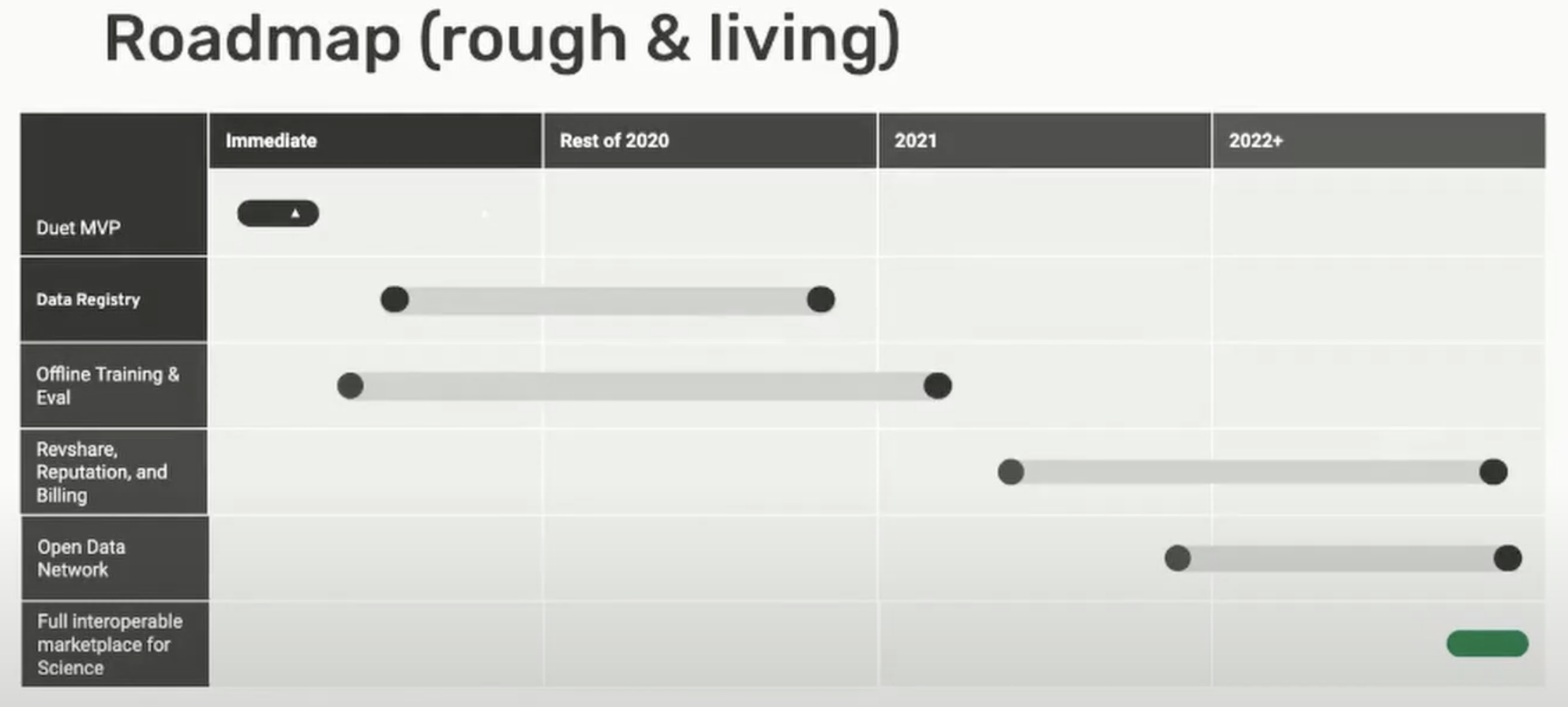
Here's our estimated development timeline:
Interested?
Duet and OpenGrid are free and open-source. Find us on GitHub, or get in touch at slack.openmined.org or email partnerships@openmined.org!
If you want to join our mission on making the world more privacy preserving:
- OpenMined Welcome Package - You can see a map of all the projects we work on here!
- Join OpenMined Slack
- Check out OpenMined's GitHub
- Placements at OpenMined