




This post is a continuation of "Remote Data Science Part 2: Introduction to PySyft and PyGrid". Previous blog was about introduction to PySyft, PyGrid and HAGrid, Visualizing the domain and about Model/Data-centric FL in "Remote Data Science"
Deploying a Single Domain Node locally using docker
Assuming that we have understood "What does a domain mean in "Remote Data Science" infrastructure?. Let's try to implement a domain.
1. Installing pre-requistes.
a. The Operating system requirements has to be as below :
- MacOS : BigSur(11.5.1)
- Linux : Ubuntu(20.04.3 - Focal Fossa)
- Windows : Windows 10
b. Ensure that "Python 3.9 or higher version" and "Pip's latest version" is installed. Pip is required to install dependencies. Use this instructions as reference for installing pip.
$ pip install --upgrade pip && pip -V (Linux)
$ python -m pip install --upgrade pip (for Windows)
c. Installing and configuring "Docker"
- Install Docker and Docker Composite V2, which is needed to orchestrate docker, as explained below:
- For Linux:
- Install Docker:
$ sudo apt-get upgrade docker & docker run hello-world
- Install Docker Composite V2 as described here.
- You should see ‘Docker Compose version v2’ when running:
$ docker compose version
- If not, go through the instructions here or if you are using Linux, you can try to do:
$ mkdir -p ~/.docker/cli-plugins
$ curl -sSL https://github.com/docker/compose-cli/releases/download/v2.0.0-beta.5/docker-compose-linux-amd64 -o ~/.docker/cli-plugins/docker-compose
$ chmod +x ~/.docker/cli-plugins/docker-compose - Also, make sure you can run without sudo:
$ echo $USER //(should return your username)
$ sudo usermod -aG docker $USER - For Windows, MacOs:
- You can install Desktop Docker as explained here for Windows or here for MacOS.
- Go to the Docker menu, click Preferences (Settings on Windows) > Experimental features.
- Make sure the Use Docker Compose V2 box is checked.
- The docker-compose should be enabled by default. If you encounter issues, you can check it by:
- Ensure at least 8GB of RAM are allocated in the Desktop Docker app:
- Go to ‘Preferences’ -> ‘Resources’
- Drag the ‘Memory’ dot until it says at least 8.00GB
- Click ‘Apply & Restart’
- Make sure you are using the dev branch of the PySyft repository (branch can be found here)
2. Create a virtual environment using python "Virtualenv" or "Conda". (Use any one of them to create an virtual environment)
1. Install python virtualenv.
$ mkdir folder_name
$ virtualenv -p python3.9 folder_name
$ source ./folder_name/bin/activate
$ deactivate (To exit out of the conda environment)
2. Install conda and create an environment. create a folder named "pysyft".
$ conda create -n
$ conda activate
$ deactivate (To exit out of the conda environment)
3. Explore locally with the PySyft API.
1. Create a folder 'syft' and make it a virtual using python virtualenv or conda. For example, creating a python virtualenv folder is as below:
$ mkdir syft
$ virtualenv -p python3.9 syft
$ source ./syft/bin/activate
$ deactivate (To exit out of the conda environment)
2. Clone PySyft from github and install syft and tox in 'syft' folder.
$ git clone https://github.com/OpenMined/PySyft.git
$ git checkout dev (Move to the correct branch in the PySyft repository)
$ pip install syft==0.6.0 (or latest syft version)
$ pip install tox
3. Install and open Jupyter notebook using tox file to login into a domain.
Open PySyft folder to access tox.ini file.
$ pip install jupyter-notebook
$ tox -l
$ tox -e syft.jupyter
If you encounter issues, you can also install it using Conda:
$ conda install -c conda-forge notebook
4. Launch domain using HAGrid command line tool
Navigate to /PySyft/packages/ from the cloned PySyft folder and launch a single domain using HAGrid command line tool. (Note that PyGrid can be accessed using command line tool or user interface)
PySyft provides a programmatic interface to easily manage and work with your node without worrying about the endpoints. Connecting to the domain node is as easy as running this line of code:
$ pip install hagrid
$ hagrid launch domain
Optionally, you can provide here additional args to use a certain repository and branch, as:
$ hagrid launch domain --repo $REPO --branch $BRANCH
First run might take ~5-10 mins to build the PyGrid docker image. Afterwards, you should see something like:

Open PyGrid admin UI, go to localhost:port_number(the port_number is 8081 by default) and login with your credentials.
Default username and password for logging into PyGrid locally are as follows:
- username : info@openmined.org
- password : changethis
5. Explore the Domain!
Note that there will not be any users or requests as we are exploring the domain for the first time.
# Shows you all the available objects on the Domain Node
domain_node.store
# Shows you all requests currently on the Domain Node
domain_node.requests
# Shows you all the user accounts on the Domain Node
domain_node.users
Detail steps for launching a domain Locally/Cloud is in the links below:
Local deployment of a domain for Linux, Windows, MacOS :
Cloud Deployment of a domain:
- Local deployment using Vagrant and VirtualBox
- Deploying on Kubernetes
- Deploy to local dev
- Deploy to Google Kubernetes Engine (GKE)
- Deploying to Azure
Illustration of launching a domain in Remote Data Science
The Covid dataset is created by a Data owner and uploaded to the Hagrid. A Data scientist requests only access to the pointers of the tensors to know the number of people tested positive.
You work at a lab, and some people have been showing symptoms of COVID19. You ask everyone to take a COVID19 test, and collect the results. However, not everyone wants their test results to be known publicly. You want to respect everyone's privacy, but at the same time you want to know if there's been a big COVID outbreak at your lab! You've heard about a brilliant scientist at CalTech named Dr. Sheldon Cooper. He says he can analyze your dataset without ever seeing it, and still tell you how many people in your lab tested positive for COVID19.
Relevant Information:
- You're the owner of a COVID19 test result dataset.
- You'll be spinning up a domain node and creating an account for a data scientist (Dr. Sheldon Cooper)
- The dataset you're giving him is a binary array, such as: [0, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1].
- In this array, each column represents a different individual who works in your lab who was tested for COVID19.
- A zero implies that they tested negative for it, and a "one" implies they unfortunately tested positively for it.
Note that as of now we are going to play both the role of a "Data owner" and as a "Data scientist" just to understand how a domain functions with an example!
1. Data owner creates a dataset, converts the dataset into private tensors and creates a login username/password for datascientist.
Create a Covid Dataset of 10 People with their covid status (0-Negative, 1-Positive)
import numpy as np
raw_data = np.random.choice([0,1],size=(10),p[0.3,0.7]).astype(np.int32)
raw_data = list(enumerate(raw_data))
raw_data

Import syft. Convert the data into tensors using sy.Tensor and make the tensor private. (Such data is called metadata which is created using differential privacy which later can be accessed by the data scientist. Each data scientist is assigned with a differential privacy budget, which reduces as the number of times the meta data is accessed.)
import syft as sy
from syft.core.adp.entity import Entity
dataset = {}
for person_index, test_result in enumerate(raw_data):
data_owner = Entity(name=f'Patient #{person_index}')
dataset[person_index] = sy.Tensor(np.ones(1, dtype=np.int32) * test_result).private(min_val=0, max_val=1, entities=data_owner)

Create a domain name ‘domain_node’. Login to the domain on Hagrid using default ID & Password.
There are two ways to log into your own node, as the Data Owner. The first way is using the PySyft library:
Via PySyft
import syft as sy
import numpy as np
from syft.core.adp.entity import Entity
domain_node = sy.login(email="info@openmined.org", password="changethis", port=8081)

Via PyGrid UI
Load the dataset to the domain created on Hagrid.
domain_node.load_dataset(assets=dataset, name="COVID19 Test Results", description="Positive/Negative COVID19 Test results", metadata="No metadata")

Check if the dataset has been created.
domain_node.datasets

Check if the user "Sheldon cooper" is created in PyGrid UI.

Observe above that the "Privacy Budget = 100" initially for data scientist "Sheldon Cooper".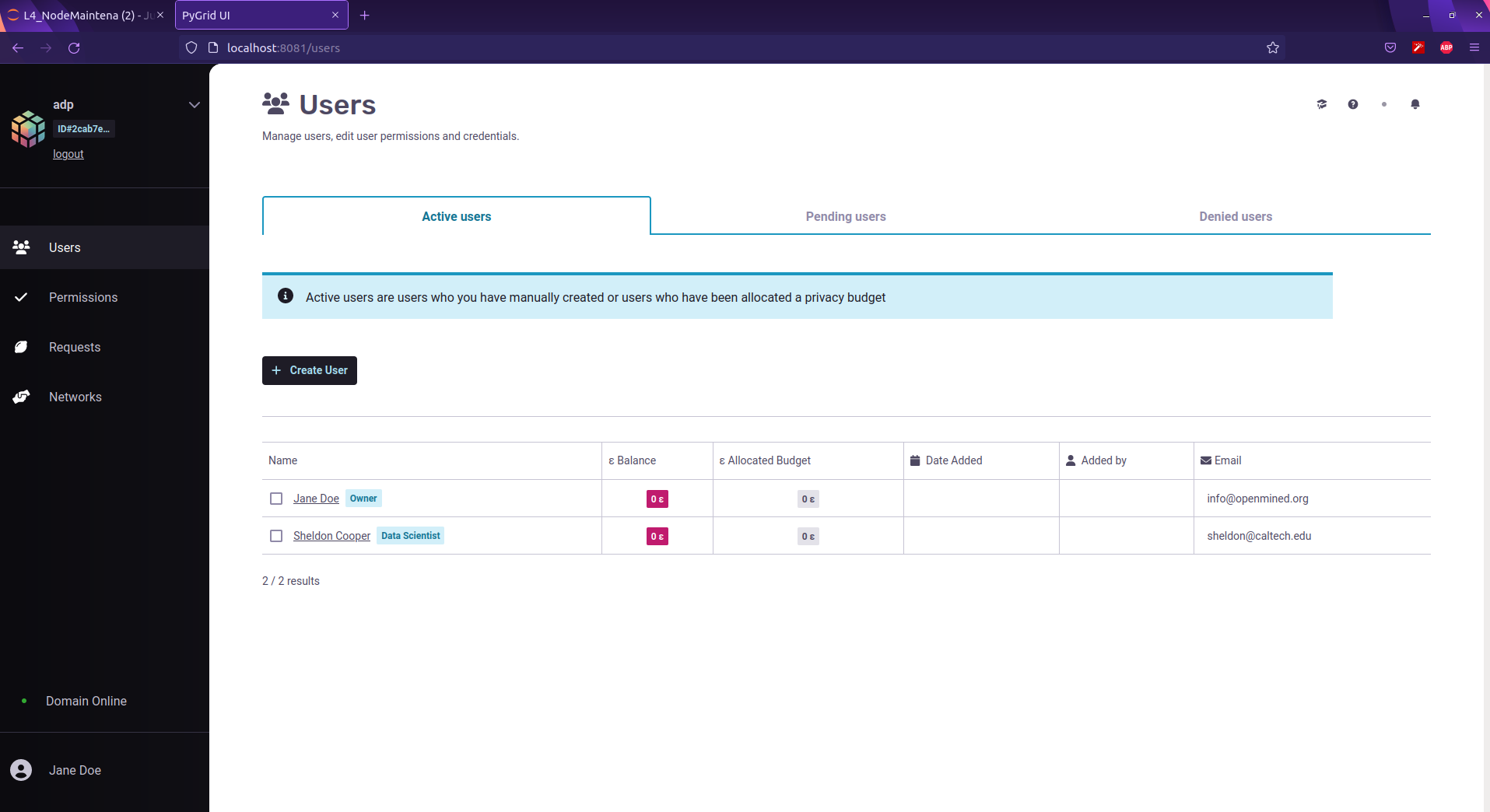
Different roles of users and managing permissions of the users
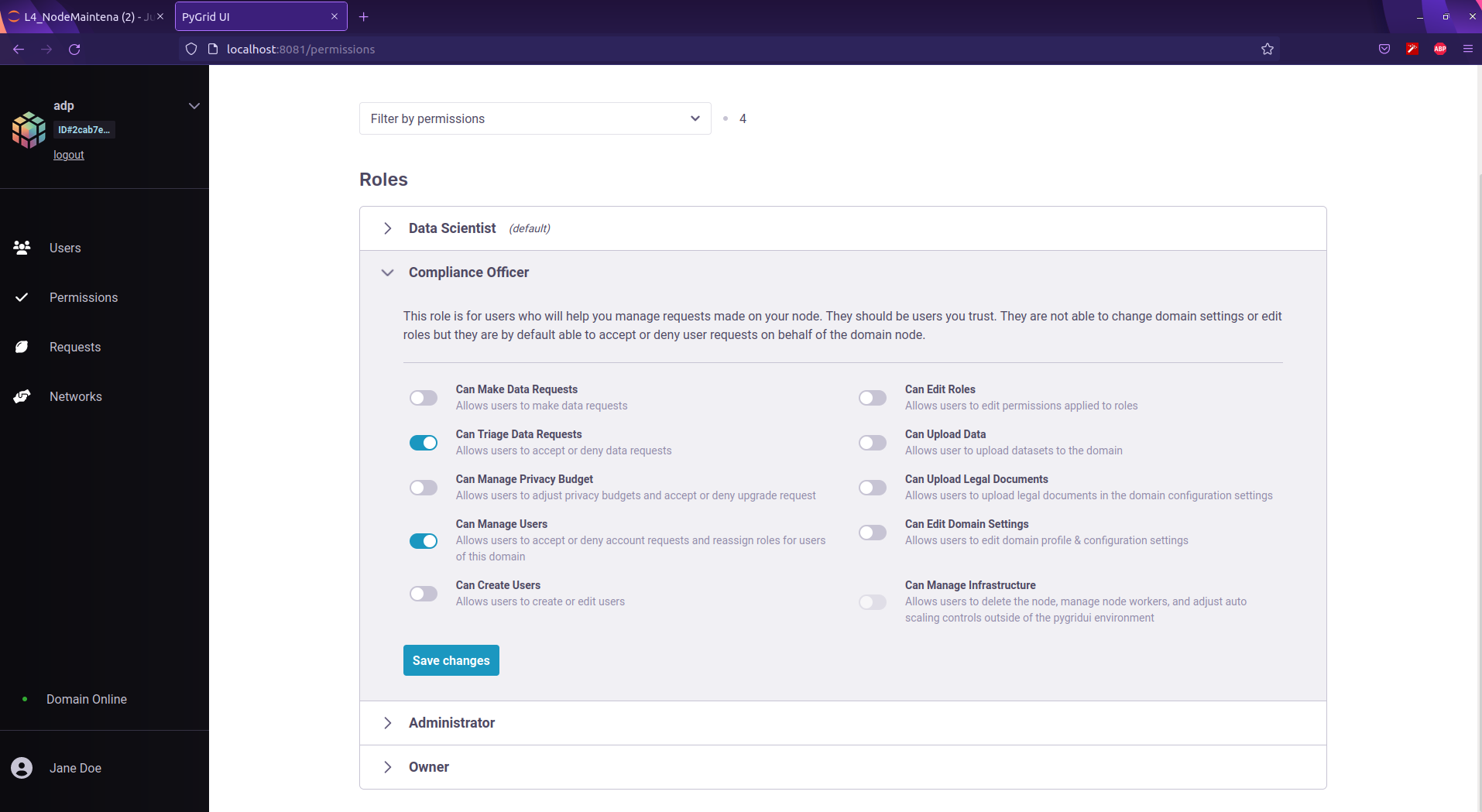
Parameters for each role can be configured as below:
2. Data Scientist logins with username/password provided by the data owner and calculates the number of covid cases.
1. Log into the Domain Node as the Data Scientist. Once a user logs into a domain, their session is saved for the next 24 hours. We will explore how a user can access a saved domain session.
import syft as sy
ds_node = sy.login(email="sheldon@caltech.edu", password="bazinga", port=8081)
2. View the available datasets on the Node
ds_node.datasets

3. Accessing specific dataset. Now, we can see the dataset that we uploaded earlier when we were the Data Owner (Jane Doe)! Now let's select our dataset:
Now, we can see the dataset that we uploaded earlier when we were the Data Owner (Jane Doe)! Now let's select our dataset:
# Let's get a pointer to the dataset
dataset = ds_node.datasets[0]
dataset

Tensor pointer of the dataset is as below:
print(dataset)
4. Calculate the total number of COVID cases
results = [dataset[f'{i}'] for i in range(10)]
from time import sleep
total_cases = 0
for result in results:
ptr = result.publish()
sleep(1)
total_cases += ptr.get()
print(f'The total number of COVID19 cases are: {total_cases[0]}')
3. Data Owner observes the decrease in privacy budget of data scientist "Sheldon Copper".
Check the privacy budget spent is 12.45 out of 100 by the data scientist who has accessed the information about “The Total number of Covid19 cases”.
domain_node.users

Finally, How do you stop the Domain node?
$ hagrid land domain_node
Thank you!
* To Andrew Trask (Leader at OpenMined) for clarifying on my questions about the domain.
* To Mark Rhode (OpenMined Communication Navigation Team Lead) for helping me revise my blog multiple times.
* To Kyoko Eng (OpenMined Product Leader) for helping me re-design the diagrams.
* To Madhava Jay (OpenMined Core Engineering Team Lead) for clarifying the architectural concepts of Remote Data Science.
* To Ionesio Junior (OpenMined AI Researcher) for providing feedback on the "Domain node example" Diagram.
* And, To Abinav Ravi (OpenMined Communication Writing Team Lead and Research Engineer) for reviewing my blog and mentoring me to coordinate with other teams.
References:
1. Introduction to Remote Data Science
2. Introduction to Remote Data science | Andrew Trask
3. Towards General-Purpose Infrastructure for protecting scientific data under study
4. UN list of Global Issues
5. Federated learning with TensorFlow Federated (TF World '19)
6. "Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI
7. Understanding the types of Federated learning.
8. What can Data-Centric AI Learn from Data and ML Engineering?
9. Turing Lecture: Dr Cynthia Dwork, Privacy-Preserving Data Analysis
10. Data-centric AI: Real World Approaches
11. OpenMined - PySyft Github Library
12. Privacy Series Basics : Definition