




Update as of November 18, 2021: The version of PySyft mentioned in this post has been deprecated. Any implementations using this older version of PySyft are unlikely to work. Stay tuned for the release of PySyft 0.6.0, a data centric library for use in production targeted for release in early December.
In this post, we provide a showcase of applying federated learning using PySyft. PySyft is an open source python library for secure and private Deep Learning from the OpenMined community. It decouples private data from model training.
In federated learning, each edge device processes its own data for training, avoiding to send it to another entity, and therefore preserving privacy. Furthermore, the main processing work for the training phase is done on the devices, so there is a reduction in necessary bandwidth and data handling compared to training in a data center. All devices learn from each other by combining their AI models, which is done by a central coordinator that can be placed in the cloud or on the edge. Since the information that is sent out of the devices are the resulting AI model updates, the risk in leaking user data is low. Techniques like secure aggregation and differential privacy can help to increase privacy.
In this example, the training will be performed on different edge devices. In our lab, we used Nvidia Jetson Tx2 devices for this purpose. The training task is an image classification task on the MNIST dataset, which contains images of handwritten digits in range 0-9. Samples of the training dataset are distributed to three workers (named Alice, Bob and Charlie) in such a way that each device only sees a range of numbers, and only trains a model with these numbers. Thanks to the combined learning, the final obtained model will nevertheless be able to recognize all numbers even though only a subset of numbers were available at each training step.
Architecture
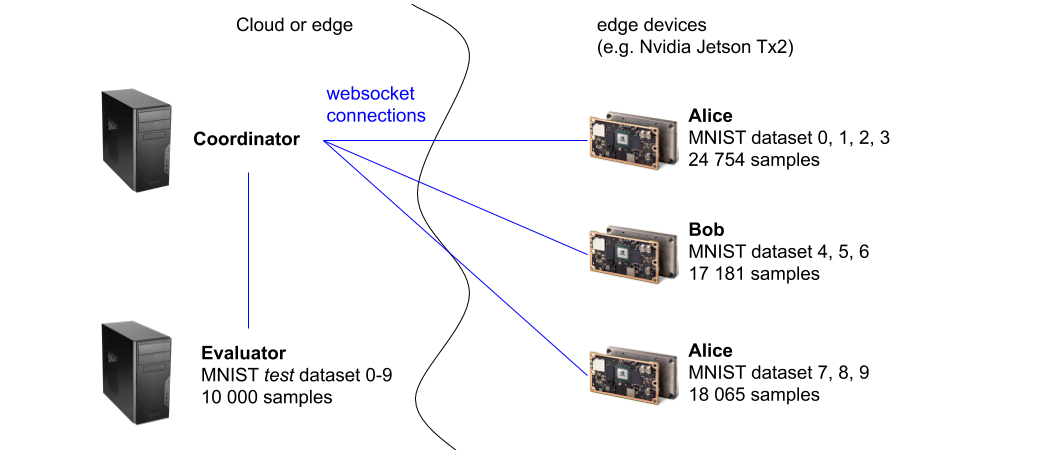
Coordinator
The coordinator is the instance that will communicate with the workers and coordinate the federated training. It receives local updates from each worker and averages the weights of the models, updating workers with the resulting averaged (combined) model.
It also creates the websocket client instances that connect to the websocket servers started on the workers and the evaluator.
Workers
The workers are the owners of their part of the training data (a selection of numbers), they train models locally and send updates to the coordinator.
They start a websocket server and wait for connections.
Evaluator
The evaluator holds the testing data set of the MNIST data set with a representation of all numbers. It is in charge of evaluating periodically the trained models, it does not perform any training.
When starting the training participants Alice, Bob, Charlie and Testing (the evaluator), they print the count of available digits, see outputs below. The first output is from the worker Alice, showing that it has 5923 examples of the digit 0, 6742 examples of the digit 1,... and no examples of the digits 4-9. The total number of examples available on Alice is 24754 examples.
$ python run_websocket_server.py --id alice --port 8777 --host 0.0.0.0
MNIST dataset (train set), available numbers on alice:
0: 5923
1: 6742
2: 5958
3: 6131
4: 0
5: 0
6: 0
7: 0
8: 0
9: 0
datasets: {'mnist': <syft.frameworks.torch.federated.dataset.BaseDataset object at 0x7fdbcd433748>}
len(datasets[mnist]): 24754
The output of Bob shows that it has a total of 17181 examples, with all examples showing digits 4-6, and no digits in the ranges 0-3 and 7-9.
$ python run_websocket_server.py --id bob --port 8778 --host 0.0.0.0
MNIST dataset (train set), available numbers on bob:
0: 0
1: 0
2: 0
3: 0
4: 5842
5: 5421
6: 5918
7: 0
8: 0
9: 0
datasets: {'mnist': <syft.frameworks.torch.federated.dataset.BaseDataset object at 0x7fea69678748>}
len(datasets[mnist]): 17181
The output of charlie shows that it only has digits 7-9 with a total of 18065 examples.
$ python run_websocket_server.py --id charlie --port 8779 --host 0.0.0.0
MNIST dataset (train set), available numbers on charlie:
0: 0
1: 0
2: 0
3: 0
4: 0
5: 0
6: 0
7: 6265
8: 5851
9: 5949
datasets: {'mnist': <syft.frameworks.torch.federated.dataset.BaseDataset object at 0x7f3c6200c748>}
len(datasets[mnist]): 18065
Finally the evaluator owns the test set of the MNIST dataset. It contains 10 000 examples distributed among all digits 0-9.
$ python run_websocket_server.py --id testing --port 8780 --host 0.0.0.0 --testing
MNIST dataset (test set), available numbers on testing:
0: 980
1: 1135
2: 1032
3: 1010
4: 982
5: 892
6: 958
7: 1028
8: 974
9: 1009
datasets: {'mnist_testing': <syft.frameworks.torch.federated.dataset.BaseDataset object at 0x7f3e5846a6a0>}
Training
Now let’s start the asynchronous federated training. For this, the coordinator creates a websocket connection to each of the workers and the evaluator.
Then it creates a model, which in our example is a neural network with 2 convolutional and 2 fully connected layers. This model starts completely untrained with random weight values.
The demo then proceeds to obtain a trained model by performing 40 training rounds.
A training round contains the following steps:
- Send the model and the training config to each of the workers
- In parallel each worker trains the model on its private data, according to the training configuration (optimizer, loss function, number of epochs/batches to train, batch size, etc)
- When the worker finishes the training, it sends its improved model back to the coordinator
- Coordinator waits for all improved models and once it gets them, it performs a federated averaging of the models to obtain one improved combined model. This improved model is sent to the workers for the next training round.
Every 10 training rounds the model (and also the individual models returned by the workers) is sent to the evaluator. The evaluator predicts the targets of the testing dataset and calculate the accuracy and the average loss.
For demo purposes the evaluator also shows the percentage of different digits returned by the models. The idea is to show that the first models returned by the workers will only return the numbers they had available locally for training. Yet after some iterations the combined model as well as the individual models returned by the workers will all predict all numbers.
An example output is shown below. It shows how the training proceeds through the 40 training rounds and evaluates the model after round 1, 11, 21 31 and 40. The evaluation after round 1 shows that each model of Alice, Bob and Charlie will classify all numbers of the test dataset as if it only contained their subset of digits. Alice will classify all numbers of the test dataset as being numbers 0-3 (percentage 100% shown below) for a total accuracy of 28.75%. Alice’s model is performing slightly better than Bob’s and Charlie’s. This is due to the fact that Alice has 4 digits available for training whereas Bob and Charlie have 3 digits each.
The federated model after training round 40 reaches an accuracy of 95.9%.
$ python run_websocket_client.py
Training round 1/40
Evaluating models
Model update alice: Percentage numbers 0-3: 100%, 4-6: 0%, 7-9: 0%
Model update alice: Average loss: 0.0190, Accuracy: 2875/10000 (28.75%)
Model update bob: Percentage numbers 0-3: 0%, 4-6: 100%, 7-9: 0%
Model update bob: Average loss: 0.0275, Accuracy: 958/10000 (9.58%)
Model update charlie: Percentage numbers 0-3: 0%, 4-6: 0%, 7-9: 100%
Model update charlie: Average loss: 0.0225, Accuracy: 1512/10000 (15.12%)
Federated model: Percentage numbers 0-3: 0%, 4-6: 86%, 7-9: 12%
Federated model: Average loss: 0.0179, Accuracy: 1719/10000 (17.19%)
Training round 2/40
Training round 3/40
Training round 4/40
Training round 5/40
Training round 6/40
Training round 7/40
Training round 8/40
Training round 9/40
Training round 10/40
Training round 11/40
Evaluating models
Model update alice: Percentage numbers 0-3: 79%, 4-6: 11%, 7-9: 9%
Model update alice: Average loss: 0.0093, Accuracy: 5747/10000 (57.47%)
Model update bob: Percentage numbers 0-3: 15%, 4-6: 76%, 7-9: 7%
Model update bob: Average loss: 0.0134, Accuracy: 5063/10000 (50.63%)
Model update charlie: Percentage numbers 0-3: 5%, 4-6: 0%, 7-9: 94%
Model update charlie: Average loss: 0.0225, Accuracy: 3267/10000 (32.67%)
Federated model: Percentage numbers 0-3: 40%, 4-6: 22%, 7-9: 36%
Federated model: Average loss: 0.0032, Accuracy: 8693/10000 (86.93%)
Training round 12/40
Training round 13/40
Training round 14/40
Training round 15/40
Training round 16/40
Training round 17/40
Training round 18/40
Training round 19/40
Training round 20/40
Training round 21/40
Evaluating models
Model update alice: Percentage numbers 0-3: 60%, 4-6: 18%, 7-9: 21%
Model update alice: Average loss: 0.0050, Accuracy: 7808/10000 (78.08%)
Model update bob: Percentage numbers 0-3: 31%, 4-6: 54%, 7-9: 14%
Model update bob: Average loss: 0.0069, Accuracy: 7241/10000 (72.41%)
Model update charlie: Percentage numbers 0-3: 21%, 4-6: 6%, 7-9: 72%
Model update charlie: Average loss: 0.0094, Accuracy: 5671/10000 (56.71%)
Federated model: Percentage numbers 0-3: 41%, 4-6: 28%, 7-9: 30%
Federated model: Average loss: 0.0017, Accuracy: 9427/10000 (94.27%)
Training round 22/40
Training round 23/40
Training round 24/40
Training round 25/40
Training round 26/40
Training round 27/40
Training round 28/40
Training round 29/40
Training round 30/40
Training round 31/40
Evaluating models
Model update alice: Percentage numbers 0-3: 59%, 4-6: 21%, 7-9: 19%
Model update alice: Average loss: 0.0044, Accuracy: 8078/10000 (80.78%)
Model update bob: Percentage numbers 0-3: 34%, 4-6: 48%, 7-9: 16%
Model update bob: Average loss: 0.0050, Accuracy: 7755/10000 (77.55%)
Model update charlie: Percentage numbers 0-3: 23%, 4-6: 9%, 7-9: 67%
Model update charlie: Average loss: 0.0124, Accuracy: 6195/10000 (61.95%)
Federated model: Percentage numbers 0-3: 41%, 4-6: 26%, 7-9: 31%
Federated model: Average loss: 0.0014, Accuracy: 9449/10000 (94.49%)
Training round 32/40
Training round 33/40
Training round 34/40
Training round 35/40
Training round 36/40
Training round 37/40
Training round 38/40
Training round 39/40
Training round 40/40
Evaluating models
Model update alice: Percentage numbers 0-3: 56%, 4-6: 23%, 7-9: 20%
Model update alice: Average loss: 0.0041, Accuracy: 8218/10000 (82.18%)
Model update bob: Percentage numbers 0-3: 33%, 4-6: 45%, 7-9: 20%
Model update bob: Average loss: 0.0039, Accuracy: 8155/10000 (81.55%)
Model update charlie: Percentage numbers 0-3: 32%, 4-6: 17%, 7-9: 50%
Model update charlie: Average loss: 0.0047, Accuracy: 7802/10000 (78.02%)
Federated model: Percentage numbers 0-3: 41%, 4-6: 29%, 7-9: 29%
Federated model: Average loss: 0.0011, Accuracy: 9592/10000 (95.92%)
If you want to run the code yourself, you can try out this jupyter notebook.
When is federated learning possible?
When working with federated learning, we also have to look at its requirements. It is useful in cases, where the data is naturally distributed and you can't or don't want to centralize it one location. Federated learning addresses this need and moves the computation-heavy part of the training to the edge devices which have limited resources. Although each individual device only is in charge of a fraction of the total workload, the resource consumption is a constraint that has to be evaluated in each scenario.
We also have to take into account the communication channels that this architecture relies on, since the workers need to communicate in the training phase with the coordinator. This gets more tricky when working over unreliable edge environments, where connectivity and security are challenges that have to be resolved.
At Midokura, we use our Edge Virtualization Platform (EVP) to take care of the deployment part, handling AI application components as microservices of a distributed architecture and enabling vertical placement of the workloads so the user can design where the workloads are processed. The platform takes care of the communication channels (which federated learning relies on), whether for an edge-edge or for an edge-cloud scenario, providing flexible connectivity, workload prioritization (QoS) and secure paths.
Conclusion
We have seen an example of how to use local (private) data in edge devices to jointly train a neural network without sending the data to a central location. Federated learning lets each client keep its data locally and trains a shared model on a coordinator by aggregating and averaging local updates.
While the design involves a central coordinator, it can be placed in the edge as well. Note this node does not see the training data, only the resulting AI models (or updates). This central node could also be placed in one of the edge devices, removing the need of a cloud instance.