




Update as of November 18, 2021: The version of PySyft mentioned in this post has been deprecated. Any implementations using this older version of PySyft are unlikely to work. Stay tuned for the release of PySyft 0.6.0, a data centric library for use in production targeted for release in early December.
Summary: In this blog we are going to provide an introduction into a new decentralised learning methodology called, ‘Split Neural Networks’. We’ll take a look at some of the theory and then dive into some code which will allow us to run them on PySyft.
Privacy and the Data industry
Historically, machine learning architectures have been built upon the assumption that all machine learning algorithms are to be centralised, where both the training data and the model are in the same location and known to the researcher. However, there is a growing appetite for learning techniques to be applied to domains where data is traditionally sensitive or private, i.e healthcare, operational logistics or finance. In healthcare, these kinds of applications have the capacity to improve patient outcomes through enhanced diagnostic accuracy and through the augmentation of doctor to patient time efficiency using competent clinical decision support systems.
However, until recently there has been a barrier in the way of this kind of innovation, data privacy. It’s currently not possible for data owners to truly know that their data hasn’t been sold on, used for something they didn’t previously consent to or held onto for far longer than intended. This leads to a problem of trust between data processors and data owners. When data has been gathered, it’s even more difficult to adequately manage the consent of its owners. This makes the traditional, centralised, industry model impossible to apply to data practices post GDPR.
For these reasons, centralised learning architectures have become either an impediment to innovation or a privacy hazard for the data owners involved. Either research on private data is blocked due to privacy ramifications or it goes ahead with potentially disastrous social and political consequences for the subjects of the data.
The tech sector still races to catch up with one of the landmark innovations of our time; blockchain. However, while distributed ledger technology is going to be at the core of the next generation of the internet, it only marks the start of a greater transformation in system architectures. The genie which has left the bottle here is decentralisation.
This principle has been adopted in order to build tools where the decentralisation of resources and multi-owner governance enshrine the citizens right to privacy and security. This opens the door to innovation through an information resource which has previously been inaccessible; private data. A community at the front of this transformation is OpenMined. Their private AI tool is called PySyft.
Split Neural Network
Traditionally, PySyft has been used to facilitate federated learning. However, we can also leverage the tools included in this framework to implement distributed neural networks. These allow for researchers to process data held remotely and compute predictions in a radically decentralised way. First introduced by MIT in December 2018, SplitNNs represent a brand new architectural mechanic for privacy-preserving ML researchers to play with.
What is a SplitNN?
The training of a neural network (NN) is ‘split’ across two or more hosts. Each model segment is a self contained NN that feeds into the segment in front. In this example Alice has unlabelled training data and the bottom of the network whereas Bob has the corresponding labels and the top of the network. The image below shows this training process, where Bob has all the labels and there are multiple Alices with X data [1]. Once the first Alice has trained, she sends a copy of her bottom model to the next Alice. Training is complete once all Alices have trained.

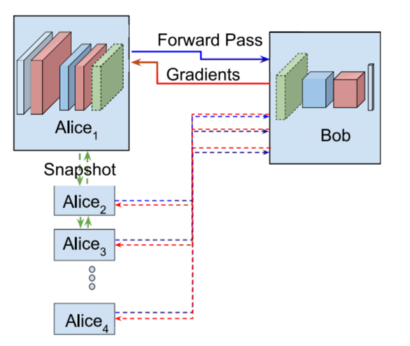
Why use a SplitNN?
The SplitNN has been shown to provide a dramatic reduction to the computational burden of training while maintaining higher accuracies when training over large number of clients [2]. In the figure below, the Blue line denotes distributed deep learning using splitNN, the red line represents federated learning (FL) and the green line labels Large Batch Stochastic Gradient Descent (LBSGD).
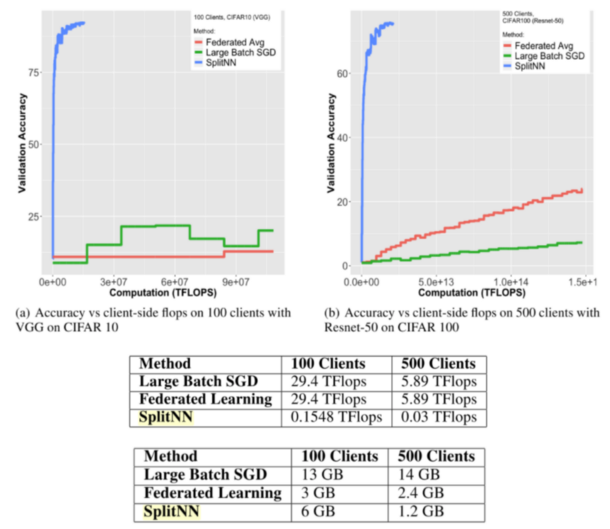
Table 1 shows computational resources consumed when training CIFAR 10 over VGG. Theses are a fraction of the resources of FL and LBSGD. Table 2 shows the bandwidth usage when training CIFAR 100 over ResNet. Federated learning is less bandwidth intensive with fewer than 100 clients. However, the SplitNN outperforms other approaches as the number of clients grow[2].
Training a SplitNN

Predictions made with a SplitNN are quite simple. All we have to do is get our data, make a prediction using the bottom segment and send that prediction to the next model segment. When that segment receives the prediction, we make a new prediction using previous one as our input data. We then send it onward to the next model. We keep going until we reach the end layer. At the end of the prediction, we have our final prediction and a computation graph for each model. Computation graphs document the transformation from the input data to the prediction and are useful in the backprop phase.
In PyTorch, the computation graph allows the autograd function to quickly differentiate variables used in a function w.r.t a loss function. Autograd produces gradients which we can then use to update the model. However, in PyTorch, this method was not designed to be distributed. We don’t have all the variables in the computation graph in one place in order to do this automatic calculation. In our method, we get around this by performing partial backprop on each model segment as we work the loss backward. We achieve this by sending the relevant gradients back as we go.
Consider the example of the computation graph below. We want to compute gradients all the way back to W₀ and B₀, which are the weights and biases in Network 1. However, our model splits at A₁. This is the output of Network 1 and the input of Network 2. To get around this, we compute the loss of O, the output of Network 2, and calculate the gradients back to A₁, W₁ and B₁. We then send the computed gradients of A₁ back to Network 1 and use them to continue the gradient calculation at that location. Once we have gradients all weights and biases all the way back to W₀ and B₀, we can step in the direction of these gradients.
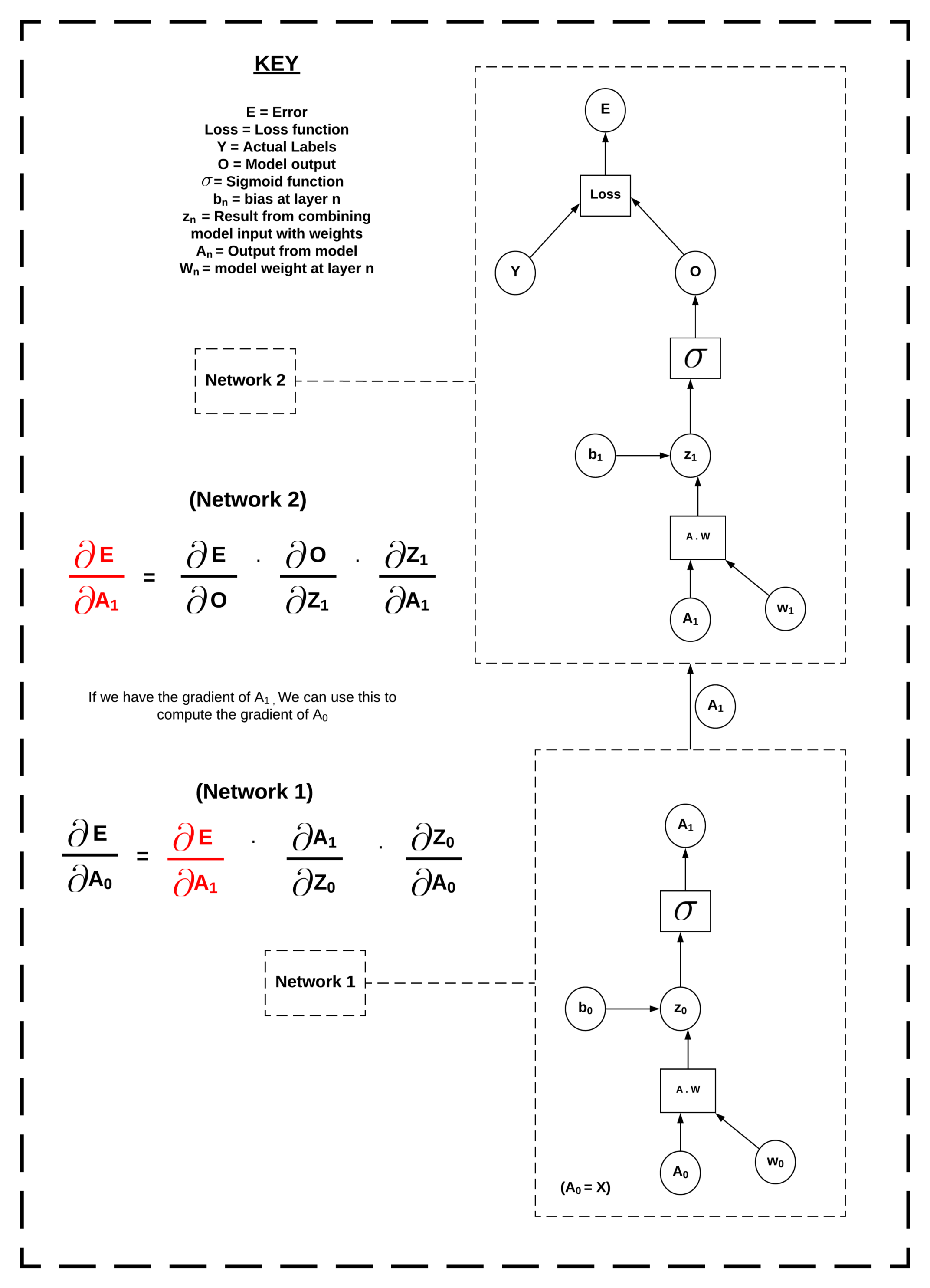
We repeat this over epochs to train the model. Once we have trained over a sufficient number of epochs, we send the model segments back to the researcher. The researcher can then aggregate the updated segments and keep the trained model.
Implementing SplitNN
Next we will go into a little code example where we use splitNN to predict upon the MNIST dataset. First we define our SplitNN class. This takes a set of models and their linked optimisers as its input.
class SplitNN:
def __init__(self, models, optimizers):
self.models = models
self.optimizers = optimizers
def forward(self, x):
a = []
remote_a = []
a.append(models[0](x))
if a[-1].location == models[1].location:
remote_a.append(a[-1].detach().requires_grad_())
else:
remote_a.append(a[-1].detach().move(models[1].location).requires_grad_())
i=1
while i < (len(models)-1):
a.append(models[i](remote_a[-1]))
if a[-1].location == models[i+1].location:
remote_a.append(a[-1].detach().requires_grad_())
else:
remote_a.append(a[-1].detach().move(models[i+1].location).requires_grad_())
i+=1
a.append(models[i](remote_a[-1]))
self.a = a
self.remote_a = remote_a
return a[-1]
def backward(self):
a=self.a
remote_a=self.remote_a
optimizers = self.optimizers
i= len(models)-2
while i > -1:
if remote_a[i].location == a[i].location:
grad_a = remote_a[i].grad.copy()
else:
grad_a = remote_a[i].grad.copy().move(a[i].location)
a[i].backward(grad_a)
i-=1
def zero_grads(self):
for opt in optimizers:
opt.zero_grad()
def step(self):
for opt in optimizers:
opt.step()
We then import all of our regular imports for training with PySyft, set up a torch hook and pull in the MNIST data.
import numpy as np
import torch
import torchvision
import matplotlib.pyplot as plt
from time import time
from torchvision import datasets, transforms
from torch import nn, optim
import syft as sy
import time
hook = sy.TorchHook(torch)
Next we define our network which will be distributed. Here we are going for a simple, three-layer network. However, we can do this for a network of any size or shape. Each segment is it’s own self-contained network. All that matters is the shape of the layer where one segment joins to the next. The sending layer must have an equal output shape to the receiving layers input shape. For more information on how the model parameters were chosen for this particular dataset, read this great tutorial.
torch.manual_seed(0) # Define our model segments
input_size = 784
hidden_sizes = [128, 640]
output_size = 10
models = [
nn.Sequential(
nn.Linear(input_size, hidden_sizes[0]),
nn.ReLU(),
),
nn.Sequential(
nn.Linear(hidden_sizes[0], hidden_sizes[1]),
nn.ReLU(),
),
nn.Sequential(
nn.Linear(hidden_sizes[1], output_size),
nn.LogSoftmax(dim=1)
)
]
# Create optimisers for each segment and link to them
optimizers = [
optim.SGD(model.parameters(), lr=0.03,)
for model in models
]
Now it’s time to define some workers to host our models, and send the models to their locations.
# create some workers
alice = sy.VirtualWorker(hook, id="alice")
bob = sy.VirtualWorker(hook, id="bob")
claire = sy.VirtualWorker(hook, id="claire")
# Send Model Segments to model locations
model_locations = [alice, bob, claire]
for model, location in zip(models, model_locations):
model.send(location)
Next we build the splitNN. All that is required for this to work is for the model segments to be in their starting locations and paired to their respective optimisers.
#Instantiate a SpliNN class with our distributed segments and their respective optimizers
splitNN = SplitNN(models, optimizers)
Next we define a train function. The usage of splitNN is fairly similar to a conventional model. All that is required is a second back-propagation phase to push gradients back over the segments.
def train(x, target, splitNN):
#1) Zero our grads
splitNN.zero_grads()
#2) Make a prediction
pred = splitNN.forward(x)
#3) Figure out how much we missed by
criterion = nn.NLLLoss()
loss = criterion(pred, target)
#4) Backprop the loss on the end layer
loss.backward()
#5) Feed Gradients backward through the network
splitNN.backward()
#6) Change the weights
splitNN.step()
return loss
Finally we train, sending data to starting locations as we go.
for i in range(epochs):
running_loss = 0
for images, labels in trainloader:
images = images.send(models[0].location)
images = images.view(images.shape[0], -1)
labels = labels.send(models[-1].location)
loss = train(images, labels, splitNN)
running_loss += loss.get()
else:
print("Epoch {} - Training loss: {}".format(i, running_loss/len(trainloader)))
The full example can be seen here on the PySyft Github.
Conclusion
There you have it, a new tool to rival federated learning in terms of accuracy, computational complexity and network resources. Follow for more updates relating to privacy-preserving methodologies such as Homomorphic Encryption and Secure Multi-Party Computation.
Author: Adam J Hall
Twitter: @AJH4LL - GitHub: @H4LL - Linkedin: Adam James Hall
If you enjoyed this then you can contribute to OpenMined in a number of ways:
Star PySyft on GitHub
The easiest way to help our community is just by starring the repositories! This helps raise awareness of the cool tools we’re building.
Try our tutorials on GitHub!
We made really nice tutorials to get a better understanding of Privacy-Preserving Machine Learning and the building blocks we have created to make it easy to do!
Join our Slack!
The best way to keep up to date on the latest advancements is to join our community!
Join a Code Project!
The best way to contribute to our community is to become a code contributor! If you want to start “one off” mini-projects, you can go to PySyft GitHub Issues page and search for issues marked Good First Issue.
Donate
If you don’t have time to contribute to our codebase, but would still like to lend support, you can also become a Backer on our Open Collective. All donations go toward our web hosting and other community expenses such as hackathons and meetups!