




Summary: This blog is a summary of the AMA with OpenMined’s NLP team lead and privacy expert Alan Aboudib(link of the video). Alan got his PhD in Computer Vision from Telecom Bretagne in France, Post doc from College de France and is currently the head of Computer Vision at “TheContillery”.
This summary will focus mainly on “Securing NLP with SyferText”, as Alan explains in the video with a high level explanation of the SyferText library which in brief is a library for privacy preserving Natural Language Processing in Python, and a code demo for training a sentiment classifier with PySyft and SyferText. So SyferText basically leverages PySyft to perform Federated Learning and Encrypted Computations (Multi-Party Computation (MPC)) on text data.
Overview
Two main use cases of SyferText are:
1) Secure Plain Text preprocessing: This is the case where the text data sets are remote or on another machine e.g. if we’re working on multiple hospitals, each hospital might have its own NLP data set that we wish to preprocess but due to some constraints like GDPR we cannot actually transfer the data to our machine or company to do centralized deep learning we need a way to send remote computing to where the data lives and start preprocessing.
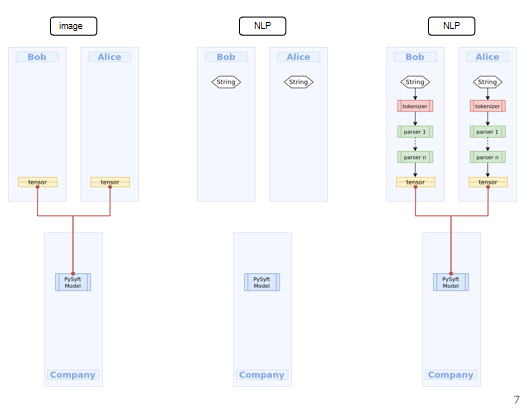
2) Secure pipeline Deploy: The second reason for using SyferText is once we create our preprocessing pipeline, we need a way to encapsulate the whole pipeline of preprocessing and to provide it as a service, so that people who identify as authorized to use that model should be able to use it.
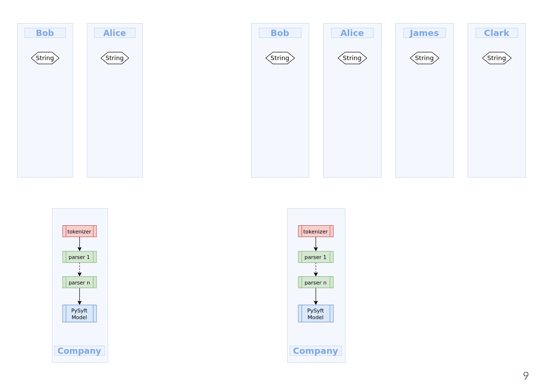
The people who will use SyferText are:
- Data Scientist: data scientist can train and deploy:
A Data Scientist or a deep learning engineer will be able to use SyferText to create these preprocessing pipelines the to train a PySyft model then to bundle it and deploy it.
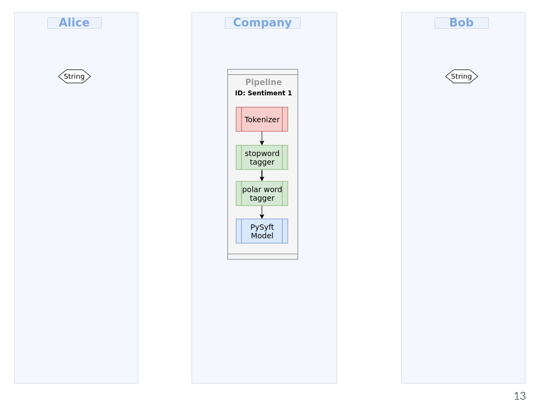
As an example let's say there are two remote clients, Bob and Alice, both Bob and Alice have strings or text data sets and we want to train a model on both data sets by concurrent training , as if both data sets were single data sets, in order to do this even if data is private. The entire workflow has been represented in the flowchart below.
Aggregate training on Bob and Alice's data
Saving the model in your company's machine
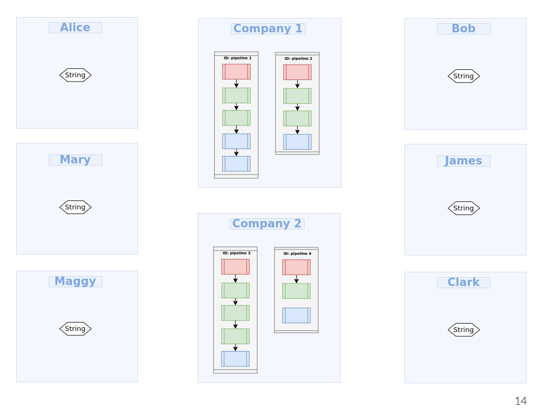
Same can be done for multiple companies
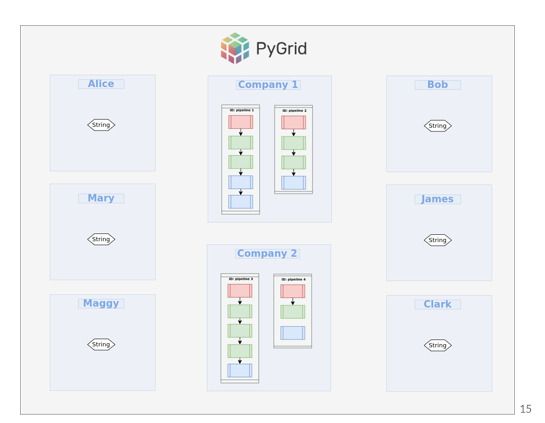
All the workers, clients and the companies will be connected with PyGrid. PyGrid is a peer-to-peer network of data owners and data scientists who can collectively train AI models using PySyft. PyGrid is also the central server for conducting both model-centric and data-centric federated learning.(Openmined's PyGrid repository)
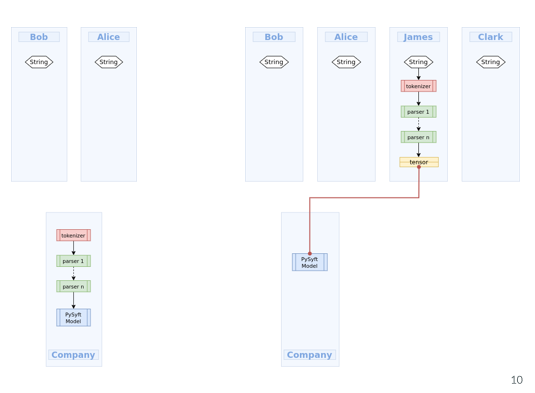
2. Data owner: the data owner can use the deployed model to do inference , e.g. if we’re a hospital we’re sitting on our machine and there is a deployed model somewhere on PyGrid with a network of secure workers we’ve we can import and use Syfertext.
Search: Lets say you're Bob and you find your sentiment classifier model
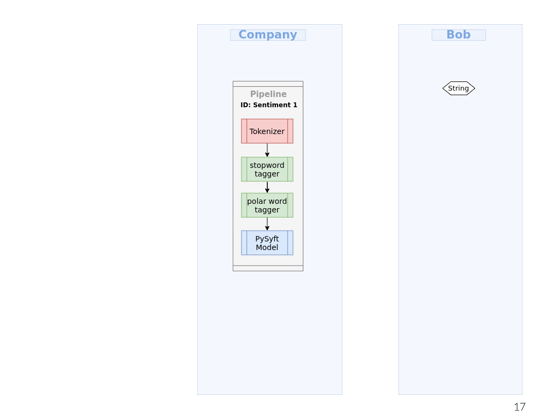
Inference:
You import SyferText, use the load function here to search for the language model, and once you find it SyferText will recognize that preprocessing part and it would recognize because of some permission parameter that the model should be used as a remote inference service. Then the pipeline will be broken into two sub pipelines, preprocessing and processing, and prediction.
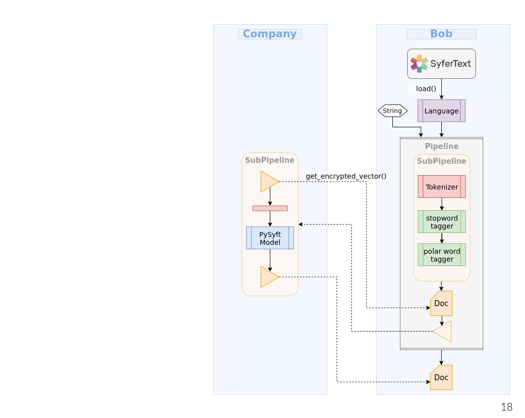
Use case
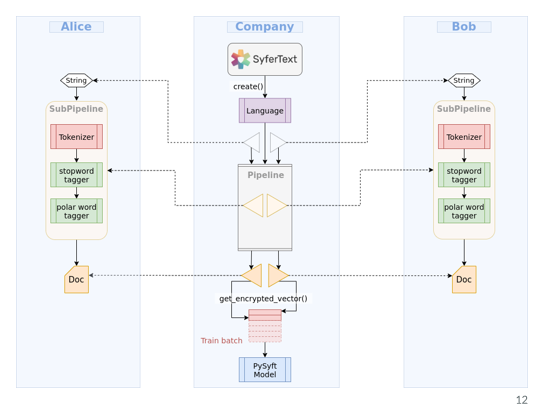
Training a sentiment classifier on multiple remote private datasets. Bob and Alice are PySyft workers and we can define them as strings.
Locally as a company we’ll be able to search for this data set. And to retrieve the data sets locally that won’t contain the data set , here represented as dictionary, each training example is dictionary,
Code demo:
Let’s suppose that we have two remote devices, which have movie reviews, using the imdb movie review dataset. And then there’s a label is it positive or negative review.
- Find the Dataset: Search for a private dataset on PyGrid
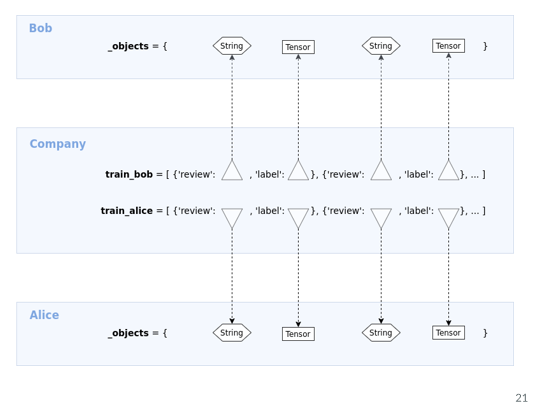
2. Secure Preprocessing:
a) Choose language model:
import syfertext
#Create a language object with Syfertext
nlp = syfertext.load(‘em_core_web_lg’, owner = me)b) Define pipes:
#Create simpleTagger object to tag pilar words
stop_tagger = =SimpleTagger(attribute = ‘is stop’,
lookups = stop_words,
tag = True,
default_tag = False
case_sensitive = False
)
#Create a SimpleTagger object to tag polar words
polarity_tagger = =SimpleTagger(attribute = ‘is_polar’,
lookups = polar_tokens,
tag = True,
default_tag = False
case_sensitive = False
)
#Create a dict of attribute:value pairs to use
#to exclude tokens for Doc vector computation
excluded_tokens = dict(is_stop = (True),
is_polar = (False)c) Add pipes:
#Add the stop word tagger to the pipeline
nlp.add_pipe(name = ‘stop tagger’,
component = stop_tagger,
remote = True
)
#Add the polarity tagger to the pipeline
nlp.add_pipe(name = ‘polarity_tagger’,
component = polarity_tagger,
remote = True
)
d) Data set class:
class DatasetIMDB(Dataset):
def __init__(self, sets, share_workers, crypto_provider, nlp):
self.sets = = sets
self.crypto_provider = crypto_provider
self.workers = share_workers
#Create a single dataset unifying all datasets.
self._create_dataset()
#The language model
self.nlp = nlp
def create_dataset(self):
“””Create a single list unifying examples from all remote datasets”””
#Initialize the dataset
Self.dataset = []
#Populate the dataset list
for dataset in self.sets:
for example in dataset:
self.dataset.append(example)
def __getitem__(self, index):
#get the example
example = self.dataset[index]
#Run the preprocessing pipeline on
#the review text and get a DocPointer object
doc_ptr = self.nlp(example[‘review’])
#smpc
# Get the encrypted vector embedding for the document
vector_enc = doc_ptr.get_encrypted_vector(bob,
alice,
crypto_provider = self.crypto_provider,
requires_grad =True
excluded_tokens = excluded_tokens
)
#Encrypt target label
label_enc = example[‘label’] fix_precision()\
.share(bob,
alice,
crypto_provider = self.crypto_provider
requires_grade = True
)\
.get()
)
return vector enc, label_enc
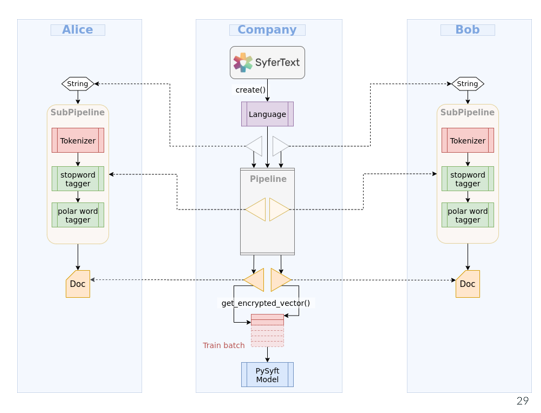
3) Secure training:
Training a sentiment classifier:
a) Define data set objects:
#Instantiate a atraining dataset object
trainset = DatasetIMDB(sets = [train_bob,
train_alice],
share_workers = [bob, alice],
crypto_provider = crypto_provider,
nlp = nlp
)
# Instantiate a validation Dataset object
valset = DatasetIMDB(sets = [val_bob,
val_alice],
share_workers = [bob, alice],
crypto_provider = crypto_provider,
nlp = nlp
)
b) Define data loaders:
#Instantiate the Dataloader object for the training s
trainloader = DataLoader(trainset,
shuffle = True,
batch_size = batch_size,
num_workers = 0,
collate_fn = trainset.collate_fn
)
#Instantiate the DataLoader object for the validation set
valloader = DataLoader(valset,
shuffle = True,
batch_size = batch_size,
num_workers = 0,
collate_fn = valset.colate_fn
)
c) Define encrypted classifier:
import syft as sy
import torch
importtorch.nn.functional as F
hook = sy.TorchHook(torch)
class Classifier(torch.nn.Module):
def __init__(self, in_features, out_features):
super(Classifier, self).__init__()
self.fc = torch.nn.linear(in_features, out_features)
def forward(self, x):
logits = self.fc(x)
probs = F.relu(logits)
return probs, logits
#Create the classifier
classifier = Classifier(in_features = 300, out_features = 2)
#Apply smpc encryption
classifier = classifier.fix_precision()\
.share(bob, alice,
crypto_provider = crypto_provider,
requires_grad = True
)
optim = optim.SGD(params = classifier.parameters(),
lr = learning_rate)
optim = optim.fix_precision()
d) Start training:
for epoch in range(epochs):
for iter, (vectors, targets) in enumerate(trainloader):
#set train node
classifier.train()
#zero out previous gradients
optim.zero_grad()
#predict sentiment probabilities
probs, logits = classifier(vectors)
#compute loss and accuracy
loss = ((probs - targets)**2).sum()
#get the predicted labels
preds = preds.argmax(dim=1)
targets = =targets.argmax(dim=1)
#compute the prediction accuracy
accuracy = (preds = =targets).sum()
accuracy = accuracy.get().float_precision()
accuracy = 100 * (accuracy / batch_size)
#backpropagate the loss
loss.backward()
#update weights
optim.step()
#decrypt the loss for logging
loss = loss.get().float_precision()
#log to tensorboard
writer.add_scalar(‘train/loss’, loss.epoch * len(trainLoader) + iter)
writer.add_scalar(‘train/acc’, accuracy, epoch * len(trainLoader) + iter)
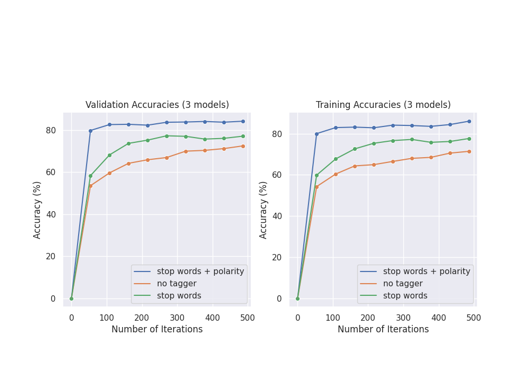
4) secure Pipeline Deploy:
a) Add trained model to pipeline:
import syfertext
#create a language object with SyferText
nlp = syfertext.load(‘en_core_web_lg’, owner = me)
#add the stop word tagger to the pipeline
nlp.add-pipe(name = ‘stop tagger’,
component = stop_tagger,
remote = True)
#add the polarity tagger to the pipeline
nlp.add_pipeline(name = ‘polarity tagger’,
component = polarity_tagger,
remote = True)
#create a dict of attribute:value pairs to use
#to exclude tokens for Doc vector computation
excluded_tokens = dict(is_stop = {True},
is_polar = {False})
#create a pipe component to create a document
#embeddings and encrypt these
Doc_encoder = DocEncoder(type = ‘avg’,
excluded_token = excluded_tokens
share_workers = [bob, alice],
crypto_provider = crypto_provider
)
#Add the document encoder to the pipeline
nlp.add_pipe(name = ‘doc_encoder’,
component = doc_encoder,
remote = True
)
#add the trained sentiment classifier to the pipeline
nlp.add _pipe(name = ‘sentiment_classifier’,
component = classifier,
remote = False)
#create a pipe component to create a document
#embeddings and encrypt them
doc_encoder = Doc_Encoder(type = ‘avg’,
excluded tokens = exclude_tokens,
share_workers = [bob, alice],
crypto_provider = crypto_provider
)
#Add the document encoder to the pipeline
nlp.add_pipe(name = 'doc_encoder',
component = doc_encode,
remote = True
)
#Add the trained sentiment classifier to the pipeline
nlp.add_pipe(name = “sentiment_classifier”,
component = classifier,
remote = False
)
b) Deploy to PyGrid:
#Deploy to Pygrid
nlp.to_grid(worker = ‘company’,
node_name = ‘Sentiment Classifier’
)Question & Answer Summary
Here's a summary of the QnA session right after Alan's demo:
Q: Is there any problem if the Data set is not same for Alice and Bob?
A: If the two Data sets are different, then that might end up being a completely different task, and of we combine both data sets into same data set then we can still train on the same task. For example if we have two hospitals, and both of them have some patient records which have similar structure, and we want to look for a cancer diagnostic in that then of course that might be p0ssible.In some cases we use "vertical federated learning", which means that data set A have some features of the data set and many features are in data set B, so we might need a more sophisticated technique to create one example out of each record.
Q: Can you discuss some use case of analyzing text in privacy preserving setting?
A: Yes in out team we're working on a project based on a research project called "Two-stage federated phenotyping and patient representation learning", where we have patient records and we need to create vector representation of these patients to create a classifier in order to create some diagnostics. it has a lot of interesting use cases in healthcare, and also some other use cases like meta-learning, in named entity recognition(when we need to exclude the entities before any preprocessing).
Q: Can you talk a little bit about Encrypted Training?
A: It is a large subject but the example above uses secure multi party encryption, which basically means that id we have a training vector on Bob and we break it into two parts or vectors that we distribute to Bob and another worker and each parameter tensor is broken onto two parts and each computation vector is broken into two workers independently and then we can actually pull back the results and get our plain text vector, the prediction should be encrypted and the worker who sent the request has the right to decrypt the request and get the results back .
Q: Does syfertext provide preprocessing over other languages like Arabic or Chinese?
A: Not yet, but its definitely something interesting to work on at some moment(rephrased).
Check out the SyferText github repository for more information.
If you want to join our mission on making the world more privacy preserving:
- OpenMined Welcome Package - You can see a map of all the projects we work on here!
- Join OpenMined Slack
- Check out OpenMined's GitHub
- Placements at OpenMined