




Abstract
Recent advances in various machine learning techniques have propelled the enhancement of the autonomous vehicles’ industry. The idea is to couple active learning with federated learning via., v2x communication, to enhance the training of machine learning models. In the case of autonomous vehicles, we almost assume that the roads will be straightforward, flat without any potholes(uncertainty), but that isn’t the case every time. Here, active learning tends to selectively choose the data points with highest informative-ness in order to label them and subsequently add them to the training pool. Additionally, with federated learning we could train our model on multiple agents in a decentralised manner on the local data that we will get from each vehicle to recognise those potholes and help try to save the vehicle from similar potholes. Also, when we think of driving in general, there are good drivers and bad drivers. So, on a 2D spectrum, we would picture a cluster of data of those drivers and realise that the good drivers’ data is clustered around a particular coordinate(x,y) on a plane while the bad drivers’ data is all over the place. Because there are numerous characteristics of bad driving but as far as good driving is concerned, they are disciplined and limited. Further, we could train our model to learn from the data that was generated by active learning. Consequently, with federated learning, we can update our model's parameters across multiple agent vehicles .
Introduction
Autonomous vehicles possess a complex system. The system is an amalgamation of many technologies including perception, prediction, sensing, localisation, mapping, interactions with cloud platforms and data storage. With the advent of autonomous vehicles and organisations looking forward to achieving level 5 autonomy, we have to shift our attention towards data, edge-to-edge computing and better machine learning models to make autonomous vehicles robust and safer for smooth navigation from one part of the world to another, while processing the data and simultaneously preserving the privacy wirelessly.
Data
In the new age of technology, data is the holy grail that every organisation is pursuing. Data labelling is a crucial and hectic task when working with computer vision data. The data-that is collected from self-driving cars is in abundance and it keeps growing after each driving test. Hence, manually labelling the data is not scalable. In computer vision, such kind of labelling task can involve drawing bounding boxes around objects and/or segmenting the objects within an image. Thus, the aspect of safety in autonomous vehicles and performance of the deep neural networks is directly dependent on labelling the data correctly to classify the objects perfectly in an image and make decisions based on the result of the network model. Incorrectly labelling the data can degrade the performance of the model.
But not every other data is important and how can we figure out which data matters the most?
Active learning
Active learning is a training data selection method that actively chooses a small subset of data points that the algorithm wants to learn from using a selection query method for training this diverse data. In the object detection and recognition task, the automatic selection process initialises with training a dedicated deep neural net on a predetermined labelled dataset, then the network sorts through unlabelled data that selects the frames it doesn’t recognise. Additionally, it doesn’t just look for frames with people, potholes, or vehicle objects but where it is most uncertain about those classes. e.g., frames that do not contain a bicycle on the road but is fixed on the back of a truck or car which can confuse the model.
To understand how active learning will work with autonomous vehicles we can look at some examples:
Good drivers and bad drivers
Let’s take task of changing lanes by autonomous vehicles for e.g., when a vehicle needs to change its lane in order to overtake the vehicle cruising in front of it, also keeping in check of the vehicle behind it and on the next lane as well. There are so many parameters that a vehicle has to check in order to make that lane change smoothly. Now, if the model learns a lane change from data that says to change the lane that is nice, but there is a problem in acquisition of such data where some humans do what may be characterized as bad lane changes. All good drivers are good in the same way and all bad drivers are bad in different ways- George Hotz, Comma.ai.( might have derived from the anna karenina principle by Leo Tolstoy )
Now, hypothetically the task is to discover the good drivers on the 2D spectrum. The good drivers stand out because they’re in one cluster, and the bad drivers are scattered all over the place and your network's task is to learn from the cluster of good drivers. They’re easy to cluster, our model learned from all of them and that automatically learns the policy of the majority. Because driving is context-dependent and depends on the visual scene and not that mainly on drivers. Let’s assume there is more than one cluster present on the plane and others are random noise and probably bad, now which one of those clusters will you choose to learn from? The problem lies with the bad drivers. How far are they from being good drivers? Here, active learning can learn from the most uncertain of the drivers, it will look for the hard negative samples from the cluster of data and try and fit the model.
Outlier detection
Outliers are the anomalies that a system comes across when training machine learning models. In simple words, outliers are exception samples that have less likelihood than a specified threshold. Thus, the removal of outliers can be the most common thought here. But, as a result, it can lead to overfit a model. Instead, just as we learn from our mistakes, outliers can prove to be a vital source of information about the data which the model is most uncertain about, such that we rectify our data training pool. Consequently, making a robust classification process.
Steps to perform the desired machine learning task:
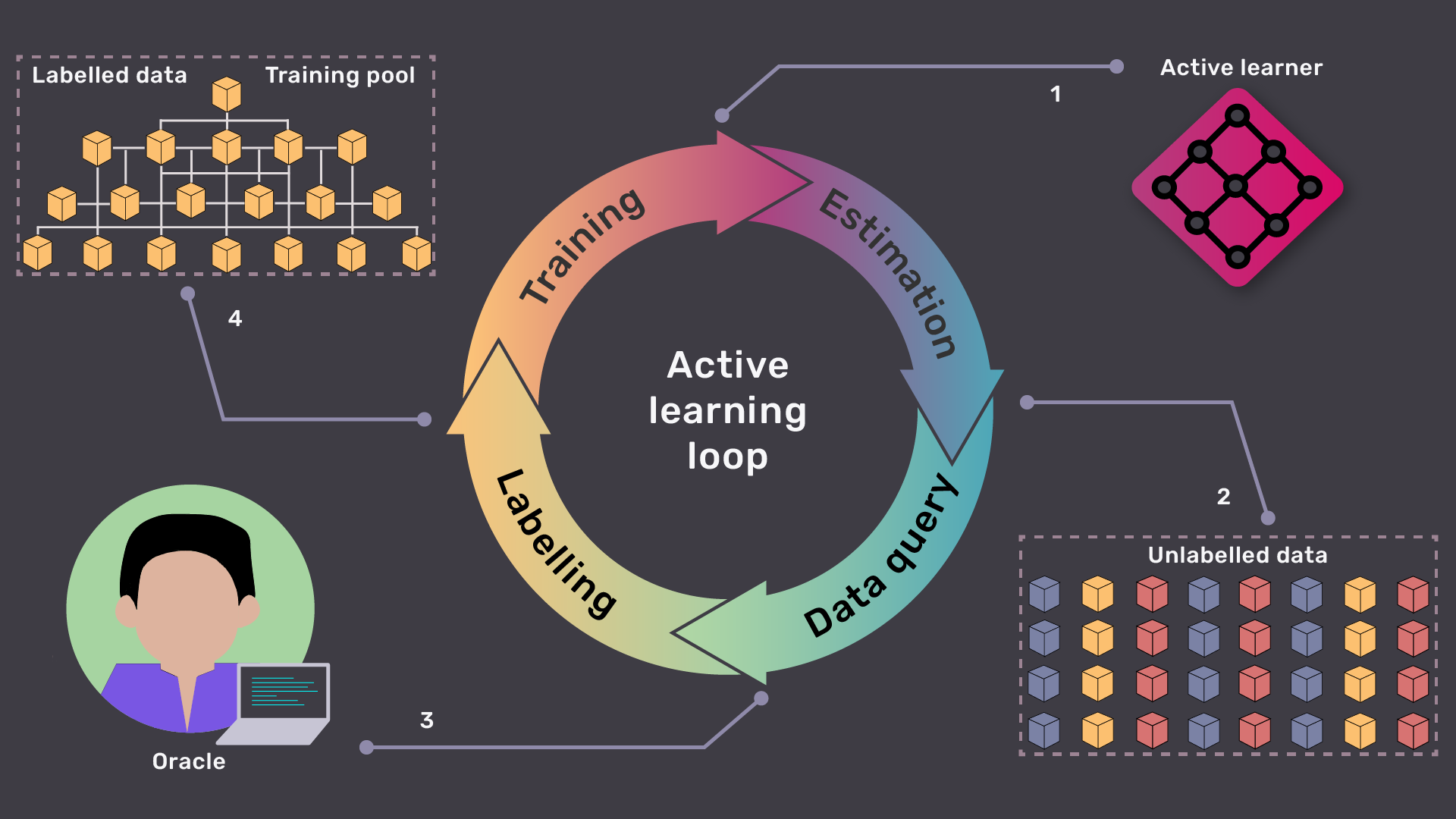
- Initialise the Active Learner(Query Selector).
- The learner then predicts the informative-ness of each data point from the unlabelled data pool and chooses the most informative unlabelled sample.
- An oracle labels the query data and adds them to the training dataset.
- The learner is re-trained on the updated dataset, that’s one iteration.
- Repeat the steps with other rounds of informative-ness estimation.
But how can we compute, process the data and federate the updated parameters across multiple autonomous vehicles?
Autonomous vehicles as edge devices
Edge computing presents a solid foundation for computing and processing the data in a distributed manner. Therefore, to process the data and train the model locally, we can use autonomous vehicles as edge devices and send relevant data as well as update parameters back-and-forth from autonomous vehicles(local models) to the central cloud(global model) respectively.
Federated learning
Federated learning is a machine learning technique that utilises the power of edge computing. Federated learning makes the model learn collaboratively in a decentralised manner while keeping all the data at the edge device itself. In simple words, ”it doesn’t take the data to where the training algorithm is; rather, bringing the algorithm to where the data is.” The biggest advantage of federated learning is that you do not have to share your data instead, the model is trained upon your data on your device itself and the parameters are updated accordingly, further aggregating it with other user’s updates to improve the shared model. Also, in federated learning, it is not necessary to have the data on a centralized server but, we have to use these tools according to our use case. In order to send the data back and forth, perform federated learning and update the model across multiple vehicles at a faster rate, there has to be a robust channel in between.
Federated learning over wireless communication?
V2X communication
The rise in wireless communication technology such as fifth-generation (5G) networks and sixth-generation (6G) networks paves the way for transferring huge chunks of data wirelessly without any packet loss. Therefore, this lower latency and higher bandwidth communication network builds a solid base for transferring data with 5G and 6G architectures at its core. V2X is a vehicle communication system that consists of many types of communications: vehicle-to-vehicle (V2V), vehicle-to-infrastructure(V2I), vehicle-to-network (V2N), vehicle-to-pedestrian (V2P), vehicle-to-device (V2D), and vehicle-to-grid (V2G).
- Let’s take an example of potholes:
Whichever vehicle has identified the pothole, avoided it, and drove around it or could have slowed down the vehicle, instead of hitting into it. That vehicle’s data and model are sent to the cloud over the network channel, where the active learner classifies the data as good driving data, and the data is then added to the training pool. Further, the model is aggregated, trained on that good driving data, and the updated parameters are then sent to the local model thereby, updating the local parameters.
Procedure

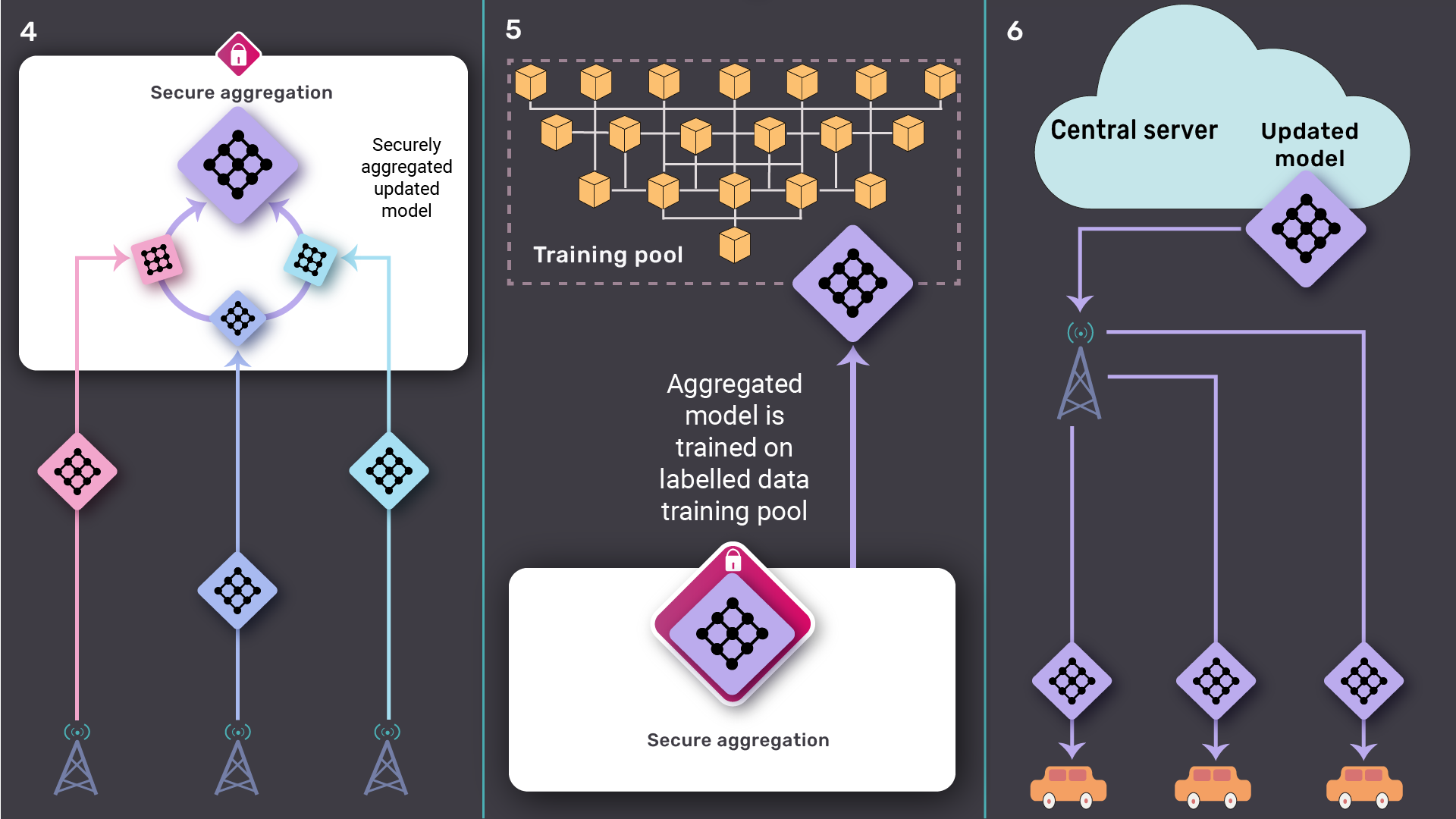
- Initially, a model is trained on the global dataset and a copy of that model is maintained across multiple autonomous vehicles.
- Driving through the city, the autonomous vehicles trains the local model on the local data that they’ve gathered and sent back the local data as well as federate the updated local machine learning models’ parameters to the cloud simultaneously at a regular interval.
- On the cloud, active learning is performed on the gathered dataset and a subset of relevant and informative data is extracted and added to the training data pool.
- Next, the local machine learning models are aggregated and the global model is updated.
- Later, The global model is then trained on the training pool.
- Lastly, the global model parameters are federated across multiple autonomous vehicles and the local machine learning models’ parameters are updated.
Conclusion
The idea is to train the model locally on the local data as well as globally on a training pool- which was generated by performing active learning on the gathered data from multiple autonomous vehicles. Further, update the parameters(weights and biases) of the model and distribute them across multiple autonomous vehicles. Whilst these techniques seems promising, they have their complications concerning security and data protection.
Nowadays, federated learning is being sold upon the notion of security and privacy but in federated learning the models can be tampered with back-door attacks and data poisoning; might as well threaten the model by performing gradient updates leading to model-poisoning. Data compression is necessary for federated learning for the smooth, faster and secure transmission of data over the network. Although it's necessary for organisation to have essential data that is needed for the data-hungry model for it to be trained upon, the individual drivers need to have some autonomy over their data - such that the individuals should have a free will to choose what ’kind’ of data they need to share with the respective organisation.
Also, with edge computing, it’s important to have reasonable energy consumption with sufficient computing power and as far as v2x communication is concerned, it is in the early stages, tackling the problems such as latency, bandwidth, reliability of the network issues and security from various attacks like DoS and distributed DoS (DDoS) attacks. Although performing federated learning and updating parameters over v2x seem possible, the parameters need to be quantised before sending over the network. Parameter quantisation will lead to the robustness of model from quantisation error. The wireless channel quality should be considered for convergence time of the model - that includes the computation time on local edge devices and the global aggregator plus the communication time in-between them. To reduce the complexity of the model and scale down model parameters, it is necessary to practise model compression and sparse training approaches over the network while maintaining the accuracy of the model. We have to think about communication cost and quality of wireless channel for model optimisation over wireless communication.
References
- What Is Active learning?
- Federated learning: collaborative machine learning without centralised training data
- V2X: What is vehicle to everything?
- Active learning: curious AI algorithms
- Scalable active learning for autonomous driving
- Anna Karenina principle
- Bad is stronger than good
- Outlier detection by active learning
- What is edge computing and why it matters?
- Edge computing for autonomous driving: opportunities and challenges
- Edge computing for AI self-driving cars
- Federated machine learning for AI self-driving cars
- Federated learning for wireless communications: motivation, opportunities and challenges
- Autonomous driving with deep learning: a survey
of state-of-art technologies
Acknowledgments
- Tom Farrand - for reviewing the blog and providing valuable insights. (Slack: @Tom Farrand)
- Kyoko Eng - for awesome suggestions/advice regarding illustrations. (Slack: @Kyoko)
- Abinav Ravi - for editing the blogpost.
(Slack: @Abinav Ravi)
For more of such blogs follow-
OpenMined:
- Twitter: https://twitter.com/openminedorg
- Slack: https://slack.openmined.org
Krunal Kshirsagar:
- Twitter: https://twitter.com/krunal_wrote
- Portfolio: https://noob-can-compile.github.io/home/
- Github: https://github.com/Noob-can-Compile
- Slack: @Krunal