




Summary: We learn best with toy code we can play with and diving into the documentations. This beginner friendly blog post covers a quick and easy explanation to Local vs Global Differential Privacy followed by simple code examples. Thank you Jacob Merryman for the amazing graphic used in this blog post. For more posts like these on Differential Privacy follow Shaistha Fathima, Rohith Pudari and OpenMined on Twitter.
Before we look into what Global or Local Differential Privacy is, let's have a quick intro to differential privacy!
So, What is Differential Privacy (DP)?
As per the most accepted definition of Differential Privacy (DP) given by Cynthia Dwork's work in the book Algorithmic Foundations of Differential Privacy.
Differential Privacy describes a promise, made by a data holder, or curator, to a data subject (owner), and the promise is like this: "You will not be affected adversely or otherwise, by allowing your data to be used in any study or analysis, no matter what other studies, datasets or information sources are available".
In a nutshell, differential privacy ensures that an adversary should not be able to reliably infer whether or not a particular individual is participating in the database query, even with unbounded computational power and access to every entry in the database except for that particular individual’s data.
DP works by adding statistical noise to the data (either to their inputs or to the output). Based on where the noise is added, DP is classified into two types - Local Differential Privacy and Global Differential Privacy.
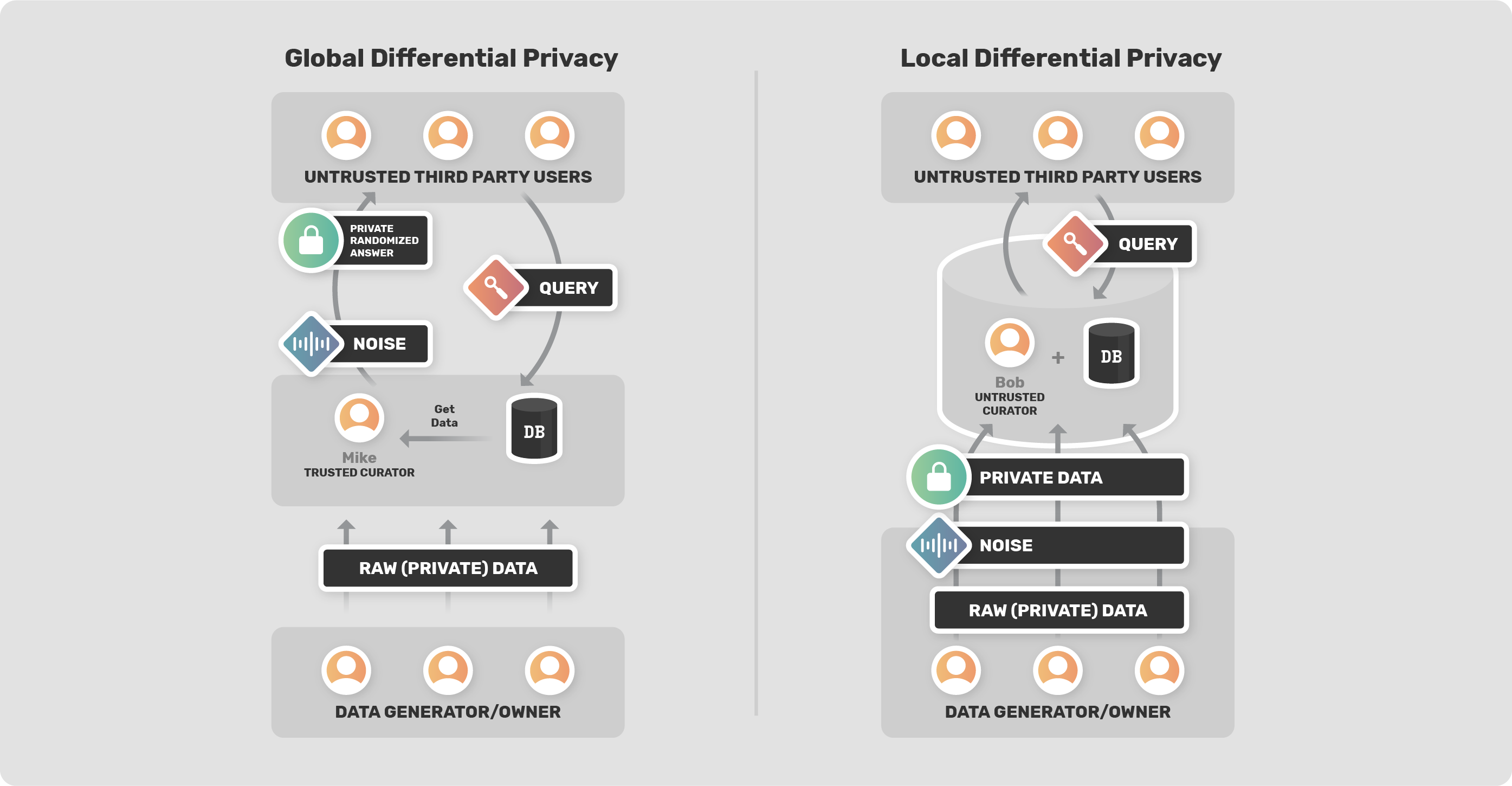
Local Differential Privacy
Local DP adds noise to the individual (input) data points. One of the simplest example would be, by Abhishek Bhowmick in Udacity's Secure and Private AI Course.
Suppose we want to know the average amount of money an individual holds in his/her pocket to be able to buy an online course? Now chances are, many might not want to give out the exact amount! So, what do we do?!
This is where Local DP comes in, instead of asking the exact amount, we ask the individuals to add any random value (noise) in the range of -100 to +100 to the amount they hold in their pockets and give us just the resultant sum of it. That is if 'X' had 30$ in his/her pocket by adding a random number say -10 to it, (30 + (-10) ), they give us just the result, which is 20$ in this case. Thus, preserving their individual privacy.
Here, the noise can be added directly to the Database or the individuals can add noise to their own datasets before putting it into the Database as seen in the above example.
Advantages - Doing this, the data curator / central aggregator, the person who is aggregating the dataset, does not know the actual value, and thus privacy is protected. The user does not have to trust the data curator or the database owner (Bob) to use his/her data responsibly.
But, since each user must add noise to their own data, the total noise is much larger. And typically would need many more users to get useful results. To mitigate this problem, practical applications often use high values of epsilon (ε).
Code Example
Suppose, we would like to take a survey on - "Did you ever steal in your life?" Chances are people would not want to participate in it and even if they do, they may lie! To come around this and get the desired results, we may use something called a randomized response!
(Note: Randomized Response is a technique used in social science when trying to learn about the high level trends for a taboo behavior such as this example, when not sure if the results are all true or may be skewed! )
Assuming a simple YES or NO answer for the above question, we follow the below steps:
- Step 1: Flip a coin 2 times.
- Step 2: If the first coin flip is heads, then take the answer (Yes/No) honestly.
- Step 3: Else if the first coin flip is tails , answer according to the second coin flip! Now the individual has to answer ‘Yes’ if it lands on heads and ‘No’ if it lands on tails. We aren’t really giving the person a choice here. This is where we add ‘randomness’.
Here is a link to understand the probability with coin flips better! - How your data is secured(by a coin toss)
Coming back to our example, think about the probability of a person responding with ‘Yes’ even though that person actually hasn’t stolen anything in their life!
For this to happen, the second coin toss has to occur and it has to land on heads. That’s because if the first toss was heads, the person would’ve told that they did not steal in their entire life. But if the first coin toss is tails and the second coin toss is heads the person will respond Yes even though the true response is No.
Thus, with the introduction of noise or randomness, each person is now protected with "plausible deniability". Each person has a high degree of protection. Furthermore, we can recover the underlying statistics with some accuracy, as the "true statistics" are simply averaged with a 50% probability. Thus, if we collect a bunch of samples and it turns out that 60% of people answered yes, then we know that the TRUE distribution is actually centered around 70%, because 70% averaged with 50% (coin flip) is 60% which is the result we obtained.
However, this comes at the cost as we are using averaged values i.e, gained privacy but have lost some accuracy. The greater the privacy protection (plausible deniability) the less accurate the results.
Let's implement this local DP for this database
# creates the initial database (db) and a parallel databases (pdbs)
def create_db(num_entries):
db = torch.rand(num_entries) > 0.5
return db, pdbsdef query(db):
true_result = torch.mean(db.float())
first_coin_flip = (torch.rand(len(db)) > 0.5).float()
second_coin_flip = (torch.rand(len(db)) > 0.5).float()
augmented_database = db.float() * first_coin_flip + (1 - first_coin_flip) * second_coin_flip
db_result = torch.mean(augmented_database.float()) * 2 - 0.5
return db_result, true_resultdb = create_db(10)
private_result, true_result = query(db)
print("With Noise:" + str(private_result)) # With Noise:tensor(0.7000)
print("Without Noise:" + str(true_result)) # Without Noise:tensor(0.5000)As the noise is being added to each data point individually, it is Local Differentially Private.
Some interesting use cases of Local DP:
- RAPPOR, where Google used local differential privacy to collect data from users, like other running processes and Chrome home pages.
- Private Count Mean Sketch (and variances) where Apple used local differential privacy to collect emoji usage data, word usage and other information from iPhone users (iOS keyboard).
- Privacy-preserving aggregation of personal health data streams paper, develops a novel mechanism for privacy-preserving collection of personal health data streams that is characterized as temporal data collected at fixed intervals by leveraging local differential privacy (Local DP)
Global Differential Privacy
In case of Global DP, noise is added to the outputs(query) of the database i.e, noise is added only once, at the end of the process before sharing it with the third party. Noise is added by the data curator/ central aggregator (Mike) to the output of a query of the database. Doing this, the data curator protects user privacy from people who are querying the database.
Data curator or the database owner (Mike) is trustworthy. The database has all the private data and a data curator has access to the real raw data.
Advantages - Accuracy!! Don't need to add a lot of noise to get valuable results with a low epsilon (ε).
But, each user has to trust the data curator enough to share data with it. That might be difficult: the aggregator can be an untrusted company or government. Also, with the global model, all the data is collected in one place. It increases the risk of catastrophic failure, for example if the aggregator gets hacked and leaks all the data.
Note: If the database owner is trustworthy, the only difference between the local and global DP is that the global DP leads to more accurate results with the same level of privacy protection. However, this requires a database owner to be trustworthy. That is the database owner/ data curator should add noise properly and protect the privacy of the user.
Code Example
With the same coin flip example as mentioned above, but, this time adding noise to the query result and not the individual data points!
def create_db(num_entries):
db = torch.rand(num_entries) > 0.5
return db, pdbsdef query(db):
true_result = torch.sum(db.float())
return true_resultData curator or aggregator adds noise before sending the result for the query i.e., adding noise to the output.
def curator(db):
noise = 0.2 # curator desides how much noise to add
db_result = query(db) + noise # curator adding noise.db, pdbs = create_db_and_parallels(10)
global_DP_result = curator(db)
true_result = query(db)
print("With Noise:" + str(global_DP_result)) # With Noise:tensor(8.2)
print("Without Noise:" + str(true_result)) # Without Noise:tensor(8.)It can be seen from the above example that the Global DP does not sacrifice much accuracy, but it is dependent on trust on the data curator.
An interesting use case of Global DP:
- Census Bureau Adopts Cutting Edge Privacy Protections for 2020 Census, that is, the US Census will use differential privacy to anonymize the data before publication.
In conclusion, When should you opt for Local DP over Global DP?
The answer to this is would be, Local DP is great for individual responses to surveys and for anytime you have private information that cannot leave devices like mobile phones. That is, when you have more user privacy concerns and cannot trust the data curator completely. But, if the data curator is trusted Global DP is a better choice with a little better results.
Distributed Differential privacy is also a type of DP but is fairly new in its practical implementation. It helps solve the problem of answering queries about private data that is spread across multiple databases. Distributed DP is beyond the scope of this blog, but, if you are interested you may read DISTRIBUTED DIFFERENTIAL PRIVACY AND APPLICATIONS to understand it better!
Interested in Differential Privacy?
Want to start contributing and learn more?
How to get involved with Differential Privacy team at OpenMined?
- Join the OpenMined Slack
- Check out OpenMined Welcome Package!
- Join the right channels that interests you (eg: #lib_pydp )
- Check out - Roadmap to Differential Privacy for All
- Join a Mentorship Program if you need some guidance.
- Check out the Good First Issues and jump right in!
References
- https://desfontain.es/privacy/local-global-differential-privacy.html
- https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf
Cover Image of Post: Photo by Andrew Ridley on Unsplash.