




As part of the PyTorch/OpenMined grants we announced last December, the Web & Mobile team has been hard at work on developing 4 new libraries for model-centric federated learning:
- syft.js - a library for federated learning in the browser
- KotlinSyft - a library for federated learning on Android devices
- SwiftSyft - a library for federated learning on iOS devices
- Threepio - a library for translating commands from one deep learning framework to another
Each of these libraries is centrally coordinated by PyGrid.
As an added bonus: we also released a 4th worker library within the PySyft project, the PySyft FL Worker, that allows for federated learning in any Python environment.
So, what is "model-centric" federated learning?
Federated Learning, at its core, is any kind of machine learning that occurs when the model is brought to the data instead of the data to the model. There are two kinds of federated learning: model-centric and data-centric.
In "model-centric" federated learning, a model's API is pre-configured (in the weights, layers, etc.) and hosted in the cloud (in our case, PyGrid). Ephemeral workers then show up, download the model, improve it, and then upload a new version. This typically happens over a long period of time (days, weeks, even months). It is most commonly found when using edge devices such as smartphones to passively improve an AI model over time, such as a model within an app.
One great example of model-centric federated learning is how Google's GBoard mobile app learns your typing preferences and style over time. Naturally, if a user were to send their text messages to Google's central servers this would be a terrible breach of privacy and would also come at great networking expense. For Google, it's also simply less expensive to use the computation power of a mobile phone than training an equivalent model in one of their data centers every time someone sends a text message. For these reasons, Google opted to leave the user's text messages on the device, train the model there, and the report the result back to Google's servers to update the global model - all without compromising a user's privacy.
In "data-centric" federated learning, a dataset's API is pre-configured (its schema, attributes, and security parameters) and is hosted in the cloud (in our case, PyGrid). Ephemeral models then show up and perform training locally in an ad-hoc, experimental way. While this form of federated learning is less common, it is more ideal for scientific exploration than model-centric federated learning as it more closely reflects the standard data science workflow.
To use an example, let's say that you want to train a model to detect cancerous nodules in CT scans. If you don't work at a major hospital, it might be very difficult or simply impossible to obtain a dataset that would be sufficient for training your model. Fortunately, with data-centric federated learning, a data owner can host their datasets in PyGrid, and you (the data scientist) can submit requests for training and inference against that data. Even better, global differential privacy may be applied to the resulting model to protect the data from being stolen out of the trained model - how cool is that!?
Great, show me the demos!
Okay, okay...
So, today marks the day that we have our initial releases of syft.js, KotlinSyft, and SwiftSyft. SwiftSyft will start in beta, while the other two are considered stable releases at 0.1.0. Currently, these libraries are locked in to PySyft 0.2.8, with the latest master branch of PyGrid. We're already working hard on version 0.3.0 to ensure more stable support in PyGrid, as well as providing support for a number of other features.
There's a few similarities between all the libraries that we should address first:
- We are hoping to add support for secure multi-party computation and secure aggregation protocols using WebRTC in the near future, but at the moment this is unsupported in PySyft.
- All libraries support optional, but suggested, JWT authentication to protect against Sybil attacks.
- KotlinSyft and SwiftSyft both have support for training either in the foreground or background. However, due to limitations with the background task scheduler in iOS, you are not guaranteed to maintain a background process for a certain amount of time. This is variable and up to the operating system to determine.
- KotlinSyft and SwiftSyft have charge detection, wifi network detection, and the capability for sleep/wake detection. These are "smart defaults" that we included to ensure that the training process doesn't interfere with the user experience or run up their cell phone's data plan. These options can each be configured as you desire.
Before we get into demos - a quick note:
All of the demos for syft.js, KotlinSyft, and SwiftSyft require the same setup process. You must run one Jupyter Notebook within PySyft. This involves having PySyft installed on your local machine, as well as having PyGrid installed on your local machine. Get those set up properly, and then run the following notebook before continuing.
syft.js

The syft.js library supports training and inference of a machine learning model inside a web browser. Let's try some sample code to see what our API looks like:
import * as tf from '@tensorflow/tfjs-core';
import { Syft } from '@openmined/syft.js';
const gridUrl = 'ws://pygrid.myserver.com:5000';
const modelName = 'my-model';
const modelVersion = '1.0.0';
// if the model is protected with authentication token (optional)
const authToken = '...';
const worker = new Syft({ gridUrl, authToken, verbose: true });
const job = await worker.newJob({ modelName, modelVersion });
job.start();
job.on('accepted', async ({ model, clientConfig }) => {
const batchSize = clientConfig.batch_size;
const lr = clientConfig.lr;
// Load data.
const batches = LOAD_DATA(batchSize);
// Load model parameters.
let modelParams = model.params.map(p => p.clone());
// Main training loop.
for (let [data, labels] of batches) {
// NOTE: this is just one possible example.
// Plan name (e.g. 'training_plan'), its input arguments and outputs depends on FL configuration and actual Plan implementation.
let updatedModelParams = await job.plans['training_plan'].execute(
job.worker,
data,
labels,
batchSize,
lr,
...modelParams
);
// Use updated model params in the next iteration.
for (let i = 0; i < modelParams.length; i++) {
modelParams[i].dispose();
modelParams[i] = updatedModelParams[i];
}
}
// Calculate & send model diff.
const modelDiff = await model.createSerializedDiff(modelParams);
await job.report(modelDiff);
});
job.on('rejected', ({ timeout }) => {
// Handle the job rejection, e.g. re-try after timeout.
});
job.on('error', err => {
// Handle errors.
});Is that it?
Yep - that's it. The greatest part of all is that you can write your model and training plan in normal PyTorch and PySyft and syft.js takes care of the rest. It's truly black magic (actually, it's not - check out the "But wait, there's more..." section for the juicy details).
KotlinSyft
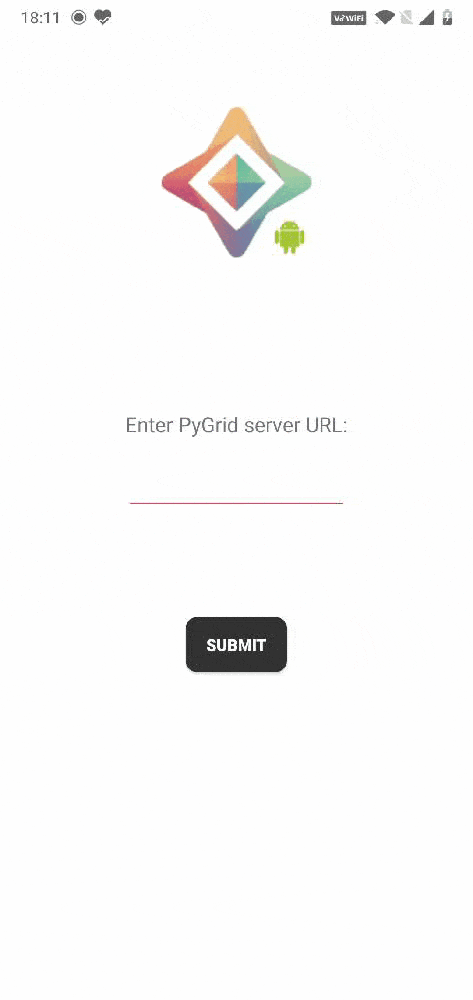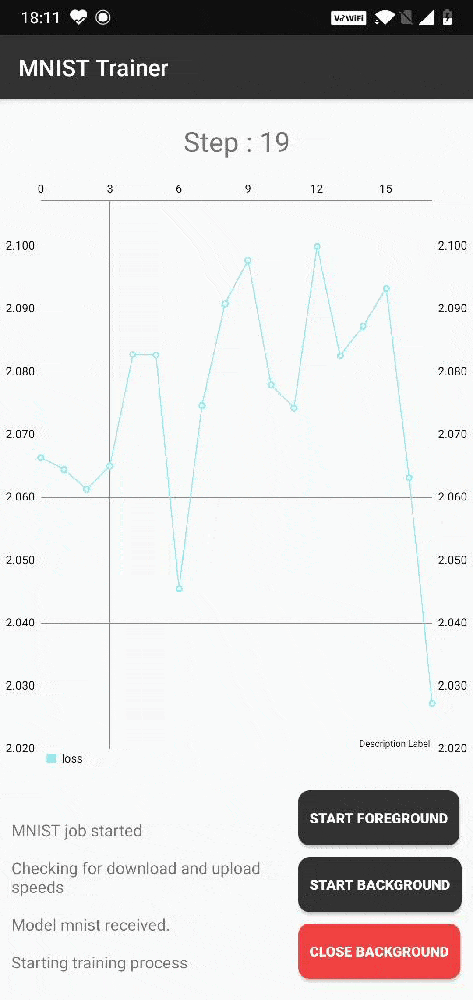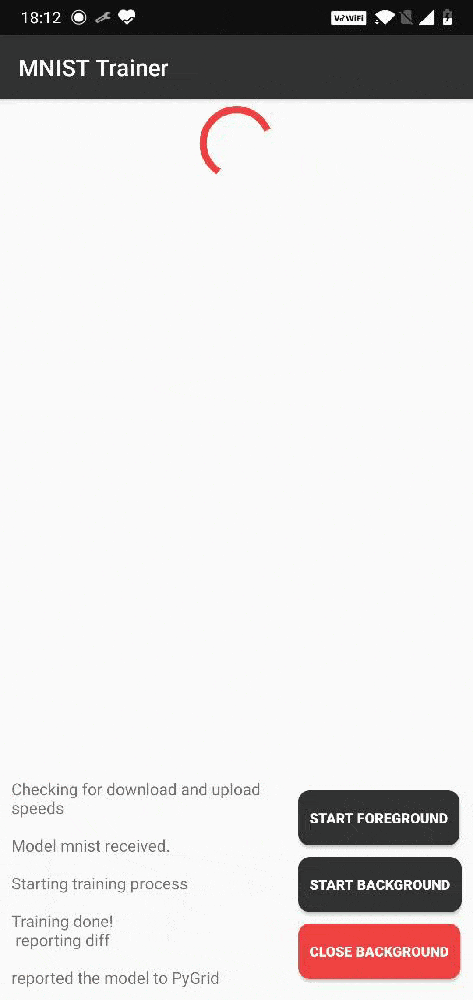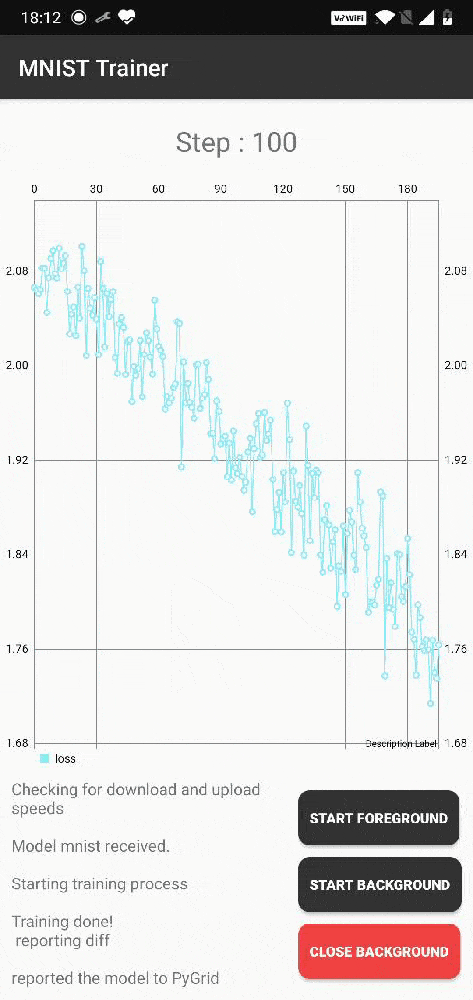
Like it's brother syft.js, KotlinSyft is a library for performing federated learning on Android devices. Here's a code snippet for the same MNIST example we showed above:
val userId = "my Id"
// Optional: Make an http request to your server to get an authentication token
val authToken = apiClient.requestToken("https://www.mywebsite.com/request-token/$userId")
// The config defines all the adjustable properties of the syft worker
// The url entered here cannot define connection protocol like https/wss since the worker allots them by its own
// `this` supplies the context. It can be an activity context, a service context, or an application context.
val config = SyftConfiguration.builder(this, "www.mypygrid-url.com").build()
// Initiate Syft worker to handle all your jobs
val syftWorker = Syft.getInstance(authToken, configuration)
// Create a new Job
val newJob = syftWorker.newJob("mnist", "1.0.0")
// Define training procedure for the job
val jobStatusSubscriber = object : JobStatusSubscriber() {
override fun onReady(
model: SyftModel,
plans: ConcurrentHashMap<String, Plan>,
clientConfig: ClientConfig
) {
// This function is called when KotlinSyft has downloaded the plans and protocols from PyGrid
// You are ready to train your model on your data
// param model stores the model weights given by PyGrid
// param plans is a HashMap of all the planIDs and their plans.
// ClientConfig has hyper parameters like batchsize, learning rate, number of steps, etc
// Plans are accessible by their plan Id used while hosting it on PyGrid.
// eventually you would be able to use plan name here
val plan = plans["plan id"]
repeat(clientConfig.properties.maxUpdates) { step ->
// get relevant hyperparams from ClientConfig.planArgs
// All the planArgs will be string and it is upon the user to deserialize them into correct type
val batchSize = (clientConfig.planArgs["batch_size"]
?: error("batch_size doesn't exist")).toInt()
val batchIValue = IValue.from(
Tensor.fromBlob(longArrayOf(batchSize.toLong()), longArrayOf(1))
)
val lr = IValue.from(
Tensor.fromBlob(
floatArrayOf(
(clientConfig.planArgs["lr"] ?: error("lr doesn't exist")).toFloat()
),
longArrayOf(1)
)
)
// your custom implementation to read a databatch from your data
val batchData = dataRepository.loadDataBatch(clientConfig.batchSize)
//get Model weights and return if not set already
val modelParams = model.getParamsIValueArray() ?: return
// plan.execute runs a single gradient step and returns the output as PyTorch IValue
val output = plan.execute(
batchData.first,
batchData.second,
batchIValue,
lr,
*modelParams
)?.toTuple()
// The output is a tuple with outputs defined by the pysyft plan along with all the model params
output?.let { outputResult ->
val paramSize = model.modelState!!.syftTensors.size
// The model params are always appended at the end of the output tuple
val beginIndex = outputResult.size - paramSize
val updatedParams =
outputResult.slice(beginIndex until outputResult.size - 1)
// update your model. You can perform any arbitrary computation and checkpoint creation with these model weights
model.updateModel(updatedParams.map { it.toTensor() })
// get the required loss, accuracy, etc values just like you do in Pytorch Android
val accuracy = outputResult[1].toTensor().dataAsFloatArray.last()
} ?: return // this will happen when plan execution fails.
// Most probably due to device state not fulfilling syft config constraints
// You should not handle any error here and simply return to close the subscriber.
// Failing to return from onReady will crash the application.
// All error handling must be done with `onError` Listener
}
// Once training finishes generate the model diff
val diff = mnistJob.createDiff()
// Report the diff to PyGrid and finish the cycle
mnistJob.report(diff)
}
override fun onRejected(timeout: String) {
// Implement this function to define what your worker will do when your worker is rejected from the cycle
// timeout tells you after how much time you should try again for the cycle at PyGrid
}
override fun onError(throwable: Throwable) {
// Implement this function to handle error during job execution
}
}
// Start your job
newJob.start(jobStatusSubscriber)
// Voila! You are done.SwiftSyft
And of course we have support for iOS via SwiftSyft. Let's see what some code samples look like for the last MNIST demo:
// Authentication token
let authToken = /* Get auth token from somewhere (if auth is required): */
// Create a client with a PyGrid server URL
if let syftClient = SyftClient(url: URL(string: "ws://127.0.0.1:5000")!, authToken: authToken) {
// Store the client as a property so it doesn't get deallocated during training.
self.syftClient = syftClient
// Create a new federated learning job with the model name and version
self.syftJob = syftClient.newJob(modelName: "mnist", version: "1.0.0")
// This function is called when SwiftSyft has downloaded the plans and model parameters from PyGrid
// You are ready to train your model on your data
// plan - Use this to generate diffs using our training data
// clientConfig - contains the configuration for the training cycle (batchSize, learning rate) and
// metadata for the model (name, version)
// modelReport - Used as a completion block and reports the diffs to PyGrid.
self.syftJob?.onReady(execute: { plan, clientConfig, modelReport in
do {
// This returns a lazily evaluated sequence for each MNIST image and the corresponding label
// It divides the training data and the label by batches
let (mnistData, labels) = try MNISTLoader.load(setType: .train, batchSize: clientConfig.batchSize)
// Iterate through each batch of MNIST data and label
for case let (batchData, labels) in zip(mnistData, labels) {
// We need to create an autorelease pool to release the training data from memory after each loop
try autoreleasepool {
// Preprocess MNIST data by flattening all of the MNIST batch data as a single array
let flattenedBatch = MNISTLoader.flattenMNISTData(batchData)
// Preprocess the label ( 0 to 9 ) by creating one-hot features and then flattening the entire thing
let oneHotLabels = MNISTLoader.oneHotMNISTLabels(labels: labels).compactMap { Float($0)}
// Since we don't have native tensor wrappers in Swift yet, we use
// `TrainingData` and `ValidationData` classes to store the data and shape.
let trainingData = try TrainingData(data: flattenedBatch, shape: [clientConfig.batchSize, 784])
let validationData = try ValidationData(data: oneHotLabels, shape: [clientConfig.batchSize, 10])
// Execute the plan with the training data and validation data. `plan.execute()`
// returns the loss and you can use it if you want to (plan.execute()
// has the @discardableResult attribute)
let loss = plan.execute(trainingData: trainingData,
validationData: validationData,
clientConfig: clientConfig)
}
}
// Generate diff data and report the final diffs as
let diffStateData = try plan.generateDiffData()
modelReport(diffStateData)
} catch let error {
// Handle any error from the training cycle
debugPrint(error.localizedDescription)
}
})
// This is the error handler for any job exeuction errors like connecting to PyGrid
self.syftJob?.onError(execute: { error in
print(error)
})
// This is the error handler for being rejected in a cycle. You can retry again
// after the suggested timeout.
self.syftJob?.onRejected(execute: { timeout in
if let timeout = timeout {
// Retry again after timeout
print(timeout)
}
})
// Start the job. You can set that the job should only execute if the device is being charge and there is
// a WiFi connection. These options are on by default if you don't specify them.
self.syftJob?.start(chargeDetection: true, wifiDetection: true)
}PySyft FL Worker
We promised you one more library. Technically, it's not a library - it's a worker within a library... but we'll go ahead and count that one. After deprecating the TrainConfig class, we have added a federated learning worker class within PySyft to take its place. If you're interested in seeing this in action, just simply run the next notebook in the series - here's a link to that.
But wait, there's more...
We also managed to release a fifth library, Threepio, a helper library running internally within PySyft (or standalone) that converts all PyTorch Plans into a list of commands for TensorFlow.js. This is required by syft.js in order to be able to execute commands inside a browser.
Threepio is a library for converting commands from one deep learning framework to another. It does this by scraping documentation of popular frameworks like PyTorch, TensorFlow, TensorFlow.js, and Numpy and then mapping commands it can intelligently identify as equivalent in all other frameworks. When a match cannot be automatically determined by name, it can also be added manually within Threepio. In addition to command names being mapped, we also have support for argument and keyword argument (kwarg) reordering.
Threepio is currently available as a library in both Python and Javascript, and also supports multi-command translation allowing commands to be mapped to other operations even when they don't directly exist in another framework.
We hope to build out further support for Threepio and need your help to achieve 100% compatibility between major deep learning frameworks. If you're interested in getting started, check out the good first issues and join our Threepio Slack channel: #lib_threepio.
What about data-centric federated learning?
Funny you should mention it - we're also in the middle of some real big developments when it comes to data-centric federated learning. We've teamed up with the University of California, San Francisco to work on building out OpenMined's data-centric federated learning capabilities in PyGrid. Stay tuned to our roadmap for more updates on what's happening in that project.
Where do we go from here?
The sky is the limit! In short, here's what to look for in terms of model-centric federated learning's near-term roadmap:
- The ability to start, stop, and pause the federated learning process in the middle of training.
- The ability to persist training data to the device or browser's local storage in the event that training fails or is interrupted by the user.
- The ability to arbitrarily execute PySyft plans without participating in a cycle
- Better, more complete documentation and testing across all our libraries, including PyGrid and PySyft.
- An easier-to-understand, and smarter
server_configin PyGrid that will allow for easier definition of cycles, their length, the number of workers allowed, and the algorithm for selection. - Support for more commands and more frameworks within Threepio
- Adding a compatibility table inside Threepio, including adding support for versioning and fuzzy finding of commands.
- Support for secure mutli-party computation and secure aggregation protocols within our various worker libraries
- Support for pre-defined averaging plans within PyGrid
Of course, I'm sure you can think of many other suggestions on what we should do next. Matter of fact - drop us a line in Slack and tell us what you think! You can find us in the #lib_syft_js, #lib_kotlinsyft, #lib_swiftsyft, #lib_threepio, and #lib_syft_mobile channels.
How do I contribute?
We'd love your support and have over 100 open issues for beginners and newcomers to the community. We could really use your help in shaping future releases and stabilization. Here's a few places you can find issues to get started on: